인터넷에 뒤져보면 python의 reduce 함수에 대해서는 많이 있는데, 정확한 명세를 알려 주는 글은 잘 없는 것 같아서 직접 정리해 본다.
reduce(func, iterable , (optional)value)
from functools import reduce
# 케이스 1
test_list = [20, 5, 4, 3]
result = reduce(lambda a, b: a - b, test_list)
print(result)
# 결과: 8
# 케이스 2
test_list = [20, 5, 4, 3]
result = reduce(lambda a, b: a - b, test_list, 100)
print(result)
# 결과: 68
func:
reduce 과정이 진행되면서 실행될 함수로, 람다 함수든 일반 함수든 상관없지만, func(a,b) 형태로 파라미터 두 개를 받아야 한다.
a는 reduce를 진행하면서 누적된 값, b는 iterable 객체에서 가져온 원소이다.
당연히 파라미터 순서가 상관 있으니, 유의해야 한다. 대부분의 인터넷 예시에선 +를 사용하여 이 점이 잘 드러나지 않아서, 일부러 -를 사용해 보았다. 만약 파라미터 순서가 바뀐다면...
from functools import reduce
test_list = [20, 5, 4, 3]
# 케이스 1에서 a-b가 b-a로 바뀐 상태
result = reduce(lambda a, b: b - a, test_list)
print(result)
# 3 - (4 - (5-20))
# 출력 : -16
iterable
list, tuple, .. 등등 순회 가능한 요소는 모두 가능하다.
value
위 케이스 1,2의 차이가 초기값의 유무이다. 이 값이 주어지지 않았다면 iterable 객체의 첫번째 원소를 초기값으로 사용하여, reduce 과정에서 맨 처음에 첫번쨰 원소와 두번째 원소에 대해 fucn을 실행한다. 위의 케이스 1에선 20 -5 가 첫번째로 수행되었다.
초기값이 주어지면, 맨 처음에 value와 첫번쨰 원소에 대해 fucn를 실행한다. 위의 케이스 2에선 100 -20이 첫번째로 수행되었다.
즉, 초기값 유무에 따라 func 함수의 실행 횟수가 1번 차이가 난다. 아래의 예시를 보면 이해가 빠를 것이다.
from functools import reduce
test_list = [20, 5, 4, 3]
def reduce_fun(a, b):
print("함수 실행")
return a - b
result = reduce(reduce_fun, test_list)
print(result)
result = reduce(reduce_fun, test_list, 100)
print(result)
""" 출력:
함수 실행
함수 실행
함수 실행
8
함수 실행
함수 실행
함수 실행
함수 실행
68
"""
reduce 코드 살펴보기
_initial_missing = object()
def reduce(function, sequence, initial=_initial_missing):
it = iter(sequence)
if initial is _initial_missing:
try:
value = next(it)
except StopIteration:
raise TypeError("reduce() of empty sequence with no initial value") from None
else:
value = initial
for element in it:
value = function(value, element)
return value
functools.py에 정의된 reduce 함수의 내용이다. 내용은 크게 어렵지 않으니 천천히 살펴보자. initial 파라미터의 유무에 따라 value=initial 또는 value =next(it)를 통해 시작값을 정의한다. 시작값이 주어지지 않았다면 이미 본격적인 reducing 과정 전에 원소를 하나 순회하므로, 순회 횟수에 차이가 생기는 것이다. 아래엔 value = function(value, element)를 통해 값을 계속 갱신한다. 이 부분을 통해 왜 fucntion의 파라미터 순서가 상관 있는지, 꼭 파라미터 2개만 들어가야 하는지 알 수 있을 것이다.
자세한 정보, 특히 복잡한 쿼리문에 대한 정보를 원한다면 이 사이트들을 방문하면 편할 것이다. 아래의 내용 역시 위 사이트를 대부분 참고하였다.
1. DynamoDB 기본
DynamoDB가 왜 필요하게 되었는가
간단하게, DynamoDB가 왜 세상에 나타났는지부터 살펴보자. noSQL류 데이터베이스를 사용하지 않고 RDB를 사용하던 시절, 아마존의 엔지니어들이 자사에서 데이터베이스를 활용하는 패턴을 분석했다. 놀랍게도 무려 90%의 연산이 JOIN을 사용하지 않았다. 또, 약 70%의 연산이 단순히 기본 키를 이용하여 하나의 행을 가져오는 key-value 형식의 연산이었다. JOIN은 매우 코스트가 큰 연산이라 JOIN을 피하기 위해, 한 마디로 성능을 위해 정규화를 포기하는 경우도 있었다. 이렇게 엔지니어들은 관계형 데이터베이스 모델의 필요성에 대해 의문을 가지게 되었다.
이와 더불어, 대부분의 RDB는 강한 일관성을 주요 특징으로 내세운다. 이 말은, 특정 연산이 실행된 이후, 모든 유저들이 해당 부분에 대해서 동일한 결과를 받아야 한다는 뜻이다. 이 점이 현실의 상황에선 어떤 문제를 갖는지 살펴보자. A는 서울에 살고, B는 브라질에 살고 있다. A가 트위터에 'hello'라는 게시물을 올렸다. RDB를 사용하는 상황이라면, A가 게시글을 올린 순간 트위터 본사가 있는 미국 서버 내 데이터베이스에 'hello'가 커밋되고, 모든 트위터 유저들은 A의 타임라인에 들어가면 'hello'가 보여야 한다. 하지만, 물리적인 거리를 고려하면 A가 글을 작성한 이후, 서울에서 미국까지 갔다가 브라질까지 가는 데 필연적으로 (컴퓨터의 세계에선) 적지 않은 시간이 소요된다. A는 글을 썼지만, B는 해당 글을 조회할 수 없어 일관성에 어긋나게 된다.
물론, 이를 해결하기 위한 방법이 있다. 서울과 브라질 각각에 데이터베이스 인스탄스를 두고, 서로 완전히 복제하도록 하는 것이다. 이 경우, 일관성을 유지하기 위해선 A가 작성한 글은 데이터베이스에 바로 커밋되지 않고, 우선 A의 글을 전 세계의 데이터베이스로 퍼뜨린 후, 동시에 커밋해야 한다. 'hello' 라는 글이 업로드됨과 동시에, 전 세계의 유저들이 저 글을 볼 수 있다. 하지만, 이 시나리오를 실현하려면 우선 여러 대의 데이터베이스를 한꺼번에 관리할 수 있는 복잡한 시스템이 필요하고, 무엇보다 A의 요청엔 불필요한 지연 시간이 생긴다. 일관성은 지켰지만, 이번엔 가용성에 문제가 생기게 된다.
이러한 문제를 해결하기 위해 역시 아마존의 엔지니어들이 고민한 결과, 강한 일관성은 지키지 않아도 된다는 결론이 나왔다. 정확히는, 은행 거래와 같이 신뢰성이 생명인 부분에선 강한 일관성이 중요하지만, 위의 트위터의 사례와 같은 대부분의 일상적 상황에선 일관성보단 가용성과 속도가 더 중요하다는 것이다. 즉, 트위터에 올린 글이 다른 사람들에게 몇 초 늦게 보여져도 크게 문제가 생기지 않는다는 점이다. 이러한 점들에서, 기본의 관계형 DB보다 일관성, 관계성을 약화하고 대신 가용성 및 확장성에 초점을 둔 DynamoDB가 탄생하게 되었다.
Table의 구조
각 테이블 안에는 item이라고 불리는 항목들이 있고, 각 항목 안에는 RDB의 column 같은 개념의 attribute(속성)들이 들어 있다. 위 그림에선 People이라는 테이블 안에 item 3개가 있고, 각 아이템 안에는 여러 가지 속성을 가지고 있다. noSQL이라는 특성상 정형화된 구조가 없기에, 각각의 아이템은 저마다 다른 구조를 가질 수 있다.
각 아이템들을 구분하는 용도로, partition key가 있다. 필수적으로 테이블에 존재해야 하며 흔히 말하는 기본 키에 해당하며, 해시 함수를 통해 각 아이템의 저장공간이 지정되며 서로 다른 값을 가져야 한다. 위의 예제에선 PersonID가 파티션 키이다. 또, 필수는 아니지만 sort key라는 테이블 내 아이템의 정렬에 사용되는 키가 있다. 이 파티션 키와 정렬 키가 합쳐서 복합 기본 키(composite primary key)로, 두 개의 속성을 합쳐서 기본 키처럼 사용할 수 있다. 이 경우, 기본 키와 정렬 키 중 하나만 달라도 서로 다른 아이템으로 인식이 될 수 있다.
또 키와 별개로 인덱스를 생성할 수 있는데, 두 가지의 인덱스가 있다. local secondary index(로컬 보조 인덱스)는 기존의 파티션 키와 함께, 지정했던 정렬 키 이외에 다른 속성을 정렬 키처럼 이용하여 테이블에 접근하고 싶을 때 사용할 수 있다.global secondary index(전역 보조 인덱스)는 아예 기존의 키와 관련없는, 새로운 구조의 키(단순 파티션 키or복합 키)를 사용하고 싶을 때 쓸 수 있다. 전역 보조 인덱스가 더 넓은 개념이라고 보면 된다.
우선, boto3.resource와 boto3.client를 불러왔다. 둘 다 AWS의 서비스를 이용하기 위한 SDK이다. 차이점이라면 resource는 client를 래핑한 고수준의 서비스이다. 따라서, client는 비교적 로우 레벨에 접근이 가능하며, resource를 이용하여 다룰 수 없는 부분을 위해 사용한다. 테이블을 부르는 건 resource.Table(테이블명)으로 간단하게 불러올 수 있지만, 처음 실행한 상태라면 아직 아무 테이블도 존재하지 않을 것이고, 따라서 맨 밑의 부분에선 오류가 뜰 것이다. 우선 테이블을 만들어 보자.
문법이 굉장히 복잡하다. 이걸 create_table에 파라미터로 그냥 박으면 가독성이 답이 없으므로 위처럼 일단 딕셔너리 형태의 변수로 뺀 후에 넣는게 제일 편할 것이다.
간단하게 스키마에 대해 설명하자면,
- TableName : 말 그대로 테이블 이름이다.
- KeySchema : 테이블에서 key로 사용할 속성들에 대해 정의해야 한다. KeyType은 'HASH'는 파티션 키, 'RANGE'는 소트 키를 나타낸다.
- AttributeDefinitions : 쉽게 말해 여기 스키마에서 언급된 키와 인덱스에 대해선 전부 여기 명시되어 있어야 한다. 키뿐만 아니라 인덱스를 쓴다면 인덱스에 명시된 속성들도 있어야 한다는 점에 유의해야 한다.
여기 쓰이는 type엔 S, N ,B 세가지가 있는데 각각 String, Number, Binary 이다. 각각의 속성에 맞춰서 넣으면 된다.
- LocalSecondaryIndexes : 위에서 언급한 로컬 보조 인덱스이다. 인덱스 이름과 키 schema를 입력한다. 위에서 봤듯이 로컬 보조 인덱스는 파티션 키를 그대로 사용하기에, 우선 기존 파티션 키를 그대로 쓰고 다음에 인덱스로 사용할 키를 정의한다. Projection은 인덱스로 복사할 속성 및 옵션을 정하는 부분이다.
GlobalSecondaryIndexes는 위의 로컬 보조 인덱스와 거의 유사하게 사용할수 있기에, 따로 언급하지 않았다.
- ProvisionedThroughput : 각각 읽기, 쓰기에 사용할 유닛(=동시에 처리 가능한 트랜잭션의 수)의 수를 정하는 옵션으로, 데이터베이스의 구조와는 관련이 없지만 트래픽에 따라 유연하게 조정할 수 있다.
이렇게 열심히 언급했는데, 솔직히 쓰면서도 좀 많이 복잡하다.
그냥 키-값 store로 사용하고자 한다면 간단하게 아래의 코드를 통해 테이블을 생성할 수 있다.
table.scan()을 통해 전체 테이블의 항목 및 아이템의 수를 위와 같이 가져올 수 있다... 인줄 알았는데 안 된다. AWS 문서에 따르면, 1MB 크기 내에서만 결과를 반환하기 때문에, 큰 데이터를 가져오려면 쿼리를 계속 불러서 페이지네이션처럼 처리해야 한다. 이는 count도 마찬가지라 정확한 테이블 내 아이템 개수를 반환한다고 보장하지 않는다.
from boto3.dynamodb.conditions import Key
table = resource.Table("TestTable")
query = {"KeyConditionExpression": Key("name").eq("키값")}
print(table.query(**query))
# 결과물은 위와 동일하게 table.query(**query)['Items']와 ['Count']로 각각 아이템과 아이템 수 조회 가능
Key나 Attr에 eq뿐만 아니라 lt, gt, between 등등 많은 조건을 붙일 수 있다.
scan과 query를 사용한 방법을 제시했는데, query는 key를 이용하여 결과를 조회하는 거라면, scan은 그냥 말 그대로 테이블 전체를 훑는 거라 큰 테이블에서 사용하면 심각한 성능 문제를 야기할 수 있다. 심지어 scan은 필터 조건을 걸어도 일단 싹 긁은 다음에 필터링 하는 방식이라, 큰 테이블에서 쓰기 힘들다. 그래서, 작은 테이블이 아닌 이상 가급적 query를 쓰는 게 좋다.
아이템을 수정하는 방식은 특이하다. 수정 대상인 키를 지정하고, UpdateExpression을 통해 자체적인 문법을 통해 업데이트 명령을 지정한다. 여기서 new_data는 임의로 정한 값으로, 변수명 앞에 콜론(:)을 붙여 내부적으로 사용하는 변수임을 나타낸다. 마지막으로, ExpressionAttributeValues를 통해 내부 변수가 어떤 값을 가지고 있는지 표현한다. 나는 새로 업데이트될 값으로 썡 문자열 'new_attttt'를 지정했는데, 값을 바꿀 속성인 att1이 인덱스나 키에 속하지 않은 이상, 당연히 여기엔 어떤 파이썬의 기본 오브젝트(숫자, 문자, 리스트, 딕셔너리 등)이 와도 괜찮다.
추가적인 파라미터인 ConditionExpression를 통해 WHERE절처럼 조건부 삭제를 할 수도 있다.
R과 U는 상세하게 설명했는데 나머지는 이렇게 한번에 설명해도 될 거 같다. 왜냐하면, 위에서 다룬 문법들을 그대로 활용하면 되기 때문이다. 예를 들어 조건부 삭제를 하고 싶으면 update의 조건부 업데이트와 똑같이 조건을 지정하면 된다. 나머지 명령들도 위에서 사용한 문법과 거의 유사하다.
get_item()은 단 하나의 아이템만 읽어 오는 함수로, 여러 개를 읽어 와야 할땐 위에서 본 scan()이나 query()를 사용하면 된다.
테이블 삭제는 워낙 간단해서 저 한줄이면 충분하다.
전체적으로 파이썬 문법보다는 aws cli를 활용하는 능력이 더 중요한 것 같다. 사실 ConditionExpression, FilterExpression과 같이 파라미터들이 이름이나 문법이나 무지하게 복잡한 이유가, 그냥 boto3 자체가 aws cli를 파이썬에서 활용할 수 있게 만든 라이브러리라, 거기서 쓰던 변수명이나 방식을 그대로 가져와서 그런 것 같다. 그래서, 어느정도 깊게 다루려면 python, boto3보다는 오히려 aws cli에 더 익숙해져야 할 것 같다.
파이썬에서 패키지 의존성을 공유할 때 가장 범용적으로 사용되는 게 requirements.txt일 것이다. 현재 파이썬 환경에서 설치된 패키지들을 정리할땐 아래의 명령어를 사용한다.
pip freeze > requirements.txt
이 명령어를 통해 설치된 패키지들이 requirements.txt에 나열된다. 이 파일을 이용하여 패키지들을 설치하고자 할 때는, 다음과 같은 명령어를 사용한다.
pip install -r requirements.txt
보통은 이 두가지 명령어 정도면 프로젝트를 관리하는 데는 지장이 없을 것이다. 하지만, 상황별로 패키지를 다르게 관리해야 할 때도 있을 것이다. 나의 경우엔, 윈도우즈 PC에서 개발을 하고 우분투 기반의 서버에서 배포를 하는데, 서버에서 위 명령어를 이용하여 패키지들을 설치할 때 오류가 생겼었다. 그래서 오류가 나는 패키지를 찾아봤는데, pywin32라는 라이브러리였고, 이 라이브러리는 파이썬에서 윈도우즈 API들을 사용할 때 쓰는 라이브러리라 당연히 에러가 날 수 밖에 없었다. 그래서, 상황에 의존성을 따로 관리해야 할 필요성을 느꼈다.
물론 일회성이고, 문제가 되는 패키지가 한두개라면 그냥 복붙으로 파일을 새로 만들고 위처럼 해도 된다. 하지만 관리해야 할 패키지가 수십 개라면 저 방법은 너무 귀찮고 헷갈릴 것이다. 그래서 조금 더 우아한 방법이 있다.
2. 조건에 따른 패키지 설치
# requirements.txt
Django==3.0.8
django-import-export==2.3.0
django-sass-processor==0.8
django-suit==2.0a1
et-xmlfile==1.0.1
Flask==1.1.2
Flask-BasicAuth==0.2.0
pycparser==2.20
pytz==2020.1
pywin32==300; sys_platform == 'win32' - 문제가 되는 라이브러리
조건을 붙이길 원하는 패키지의 뒤에 ;를 붙이고, 조건을 넣는다. 나는 윈도우즈 플랫폼에서만 해당 패키지를 설치하길 원해서 윈도우즈 플랫폼에서만 해당 라이브러리를 설치하도록 설정하였다. 만약 리눅스에서만 설치하기 원하는 패키지라면 sys_platform == 'linux' (python2는 linux2)로 설정하면 된다.
위 내용에 대한 정보는 여기를 참조하면 된다. 해당 문서에서 소개하는 주요 마커들은 다음과 같다.
예를 들어, 파이썬의 버젼(2.7, 3.5, 3.6, ...)에 따라서도 다르게 설정하길 원한다면 python_version == "원하는 버젼"을 붙이면 될 것이다.
3. 파일을 아예 분리하기
위에 제시된 마커들로는 구분할 수 없는 정보가 있거나, 분리해야 하는 패키지가 너무 많다면 아예 파일을 나눠버릴 수 있다.
이런 식으로, 다른 파일을 읽어오도록 설정할 수 있다. 예를 들어, 배포 환경에선 `pip install -r requirements-production.txt` 명령어를 실행한다. 그러면 우선 requirements.txt를 읽어와서 그 안의 패키지를 설치하고, 그 다음엔 requirements-production.txt 에 적혀 있는 라이브러리들을 설치하게 된다. gunicorn, uwsgi와 같은 배포에만 필요한 라이브러리들이 여기에 들어가면 될 것이다.
관리해야 하는 패키지들이 간단하다면 역시 파일 하나로 모든 게 가능한 2번 방법, 조금 구조가 복잡하다면 3번 방법이 가장 적절할 것이다. 자세한 정보는 여기서 확인할 수 있다.
인턴으로 다니던 회사에서 데이터를 주기적으로 크롤링하고, 크롤링한 자료를 이용자들에게 제공해주는 웹 서버를 개발했다. 이 서버를 운영해야 하는데, 이 모든 작업이 정상 작동하는지 주기적으로 확인을 해야 한다. 서버는 사실 바로 안다. 그냥 주소를 입력했는데 안 들어가지면 문제가 있다. 내가 확인하기도 전에 아마 사용자 측에서 뭔가 피드백이 들어올 것이다.
하지만, 크롤링이 잘못되었을 경우엔 이 크롤링이 잘못되었다는 사실을 깨닫는 건 상대적으로 까다롭다. 그냥 데이터가 몇 개 비거나, 혹은 아예 안 보일 뿐이지 다른 모든 건 정상작동 할 것이다. (서버와 크롤링 모듈을 합쳐놓지 않은 이상) 물론, 서버 로그를 확인하는 방법도 있다. 하지만 AWS를 사용하는 지금으로선 putty를 켜고 들어가는 거 자체도 너무 귀찮았다. 그래서 그냥 이 과정을 자동화 시켜서, 나는 그냥 앉아서 정상 작동 여부를 알도록 했다.
해당 크롤링이 성공이든, 실패든 일단 무조건 메세지를 보내서 성공/실패를 보고하도록 하고 싶었다. 일단 언어는 크롤링 모듈이 python으로 만들어 졌기에 python으로 고정하고, 이제 이 메세지를 보낼 매체를 선정하는데, 선정 결과는 다음과 같았다.
- 이메일 : 프로토콜도 있고 다 있는데, 이미 내 네이버 메일함은 999+라 메일 공해를 더 일으키고 싶진 않다. 그렇다고 업무용 메일을 또 만들기엔 솔직히 내가 확인을 자주 안 할거같다.
- 카카오톡 : 접근성도 최고고, 다 좋은데 사적 메신저를 업무용으로 쓰고 싶진 않았다. 결정적으로, 현재 메세지 보내는 API 서비스가 종료하고 새로운 챗봇 서비스를 준비하는 모양인데, 이게 2020년 2월 기준으로 베타 테스트 중이라 사유를 적어서 신청해야 쓸 수 있다.
- 텔레그램 : telegram이라는 모듈이 있어서 코딩하기엔 편리한데, 이것도 사실 업무용보다는 사적인 메신저라 업무용으로 쓰고 싶진 않았다.
- Slack : slacker라는 쓰기 쉬운 모듈도 있고, 원래 업무용으로 나온 메신저다.
그래서 Slack bot을 만들기로 했다.
2. Slack bot 추가하기
일단 당연히 Slack 워크스페이스를 만들어야 한다. 다행히 만드는 건 무료다. 무료 기능은 검색 기능이 15000 메세지로 제한되는 점을 빼면 개인적으로 사용하는 수준에선 딱히 지장이 없을 것이다. 사실 실무에서 slack을 사용하고 있었다면 이미 유료 에디션일 것이다.
일단, 봇은 여기서 app이라고 부르는 데 이 app을 만들어야 한다.
https://api.slack.com/ 여기로 본인 아이디로 로그인하고, 화면 중앙의 Start building -> Create New App을 클릭한다.
본인이 쓸 앱 이름과 이 앱이 적용될 워크스페이스를 지정한다. 아까 만든 워크스페이스를 지정하면 될 것이다.
이제 앱은 생성되었고, 설정을 할 시간이다. 보면 bots와 같이 사용자와 인터렉션을 할 수 있도록 다양한 옵션이 준비되어 있는데, 지금 만드는 것은 양방향 소통이 아니라 일방적으로 정보를 전송해 주는 구독형 봇이라 Permissions만 손대보자.
들어가면 우선 Install App to Workspace라고 이름만 보면 반드시 눌러야 할 거 같이 생겼는데 안 눌리는 버튼이 있다. 당황하지 말고 지금은 권한이 아무것도 지정이 안 되어서 설치를 못 하는 것이다. 스크롤을 내리자.
밑에 Scopes에서, 우리는 Bot으로 쓰는 거니 Bot Token Scope에서 지정해보자. 여러 가지 권한들이 있는데, 내가 사용할 것은 chat:write 다. chat:write는 당연히 글을 써야 하니 주는 기능이다. 클릭하면 바로 적용이 된다.
이외에도 사용 가능 IP 제한 설정이나 리디렉션 설정 등이 있다. 필요한 설정이 있다면 하면 되고, 이제 다시 보면...
이제야 인스톨 앱 버튼이 활성화가 됐다. 다음엔 이런 권한을 준다고 확인창이 뜨는데, 읽어보고 자기가 준 권한이 맞다면 승인을 누르자.
Bot 토큰을 받는데, 이 토큰으로 봇을 조종하니 유출되지 않게 하자.
그리고 이 봇이 들어갈 채널을 만들자. 테스트인데 그냥 #test면 심심하니까 #testtest로 했다.
눌러야 하는 버튼이 보인다. Add an app을 누르자.
아까 만든 TestService가 보인다. Add를 하면 채널에 초대가 된다.
그런데, 처음 만들 땐 Add가 아니라 그냥 View로 보이면서 초대가 안 될 때가 있다. 이 경우는 그냥 기다리니까 다 해결이 됐는데, 내 추측으로는 앱이 만들어졌다는 사실 자체는 바로 전송되는데, 앱이 해당 워크스페이스에 적용되는 데는 시간이 걸리는 것 같다.
초대가 됐다. 참고로 아이콘이나 이름을 편집하고 싶다면, 앱 관리 페이지의 Basic Information에서 이름이나 아이콘 등을 바꿀 수 있다.
이걸로 모든 준비가 끝났다.
3. Python 코드 작성
pip install slacker를 통해 라이브러리를 설치한다.
사용은 놀랍도록 간단하다.
# Slackbot.py
from slacker import Slacker
from datetime import datetime
token = '아까 받은 토큰을 이곳에 삽입'
def send_slack_message(msg, error=''):
full_msg = msg
if error:
full_msg = msg + '\n에러 내용:\n' + str(error)
today = datetime.now().strftime('%Y-%m-%d %H:%M:%S ')
slack = Slacker(token)
slack.chat.post_message('#testtest', today + full_msg, as_user=True)
if __name__ == "__main__":
# 일부러 에러가 발생하도록 함.
try:
a = 1/0
except Exception as e:
send_slack_message('테스트', e)
사실 메세지 전송 자체는 딱 import 한 줄, token 한 줄, slacker 두 줄로 총 네 줄이면 충분한데, 나는 해당 에러 발생 시간도 알기 위해 시간 정보 역시 삽입했다. 아래의 __main__ 코드를 통해 에러를 발생시켜보자.
다음과 같이 메세지가 보내어진다. 기본적으론 이게 끝이다!
4. 프로젝트에서의 활용
이번엔 내가 사용했던 용례를 소개하고자 한다. 우선, 가장 기본적으론 이렇게 사용할 수 있겠다.
def run():
# 여기에서 크롤링 진행
if __name__ == "__main__":
try:
run()
send_slack_message('크롤링이 완료되었습니다.')
except Exception as e:
send_slack_message('크롤링 작업 중 오류가 발생했습니다!', e)
이러면 run()이 오류 없이 진행되었을 시, 크롤링이 완료되었습니다 라는 메세지가 보내지고, 에러가 나면 에러내용과 함께 에러가 발생했다는 메세지가 전송된다. 성공을 하든 실패를 하든 일단 메세지를 보내게 된다. 만약 정해진 시간에 아무런 메세지도 안 온다? 이러면 아예 실행 자체가 안 된 것이니 역시 서버를 체크하면 된다. 성공의 경우도 메세지를 보내야 하는 이유가, 서버가 OS 다운 등의 모종의 사유로 아예 스크립트를 못 돌리는 상황도 체크하기 위함이다.
하지만 이 경우는 단순히 크롤러의 성공/실패 여부만 따질 뿐, 문제가 있다. 말 그대로 프로그램을 돌릴 수 없는 '에러' 만 잡는 상황이고, 의도하지 않는 값이 나오는 경우는 잡을 수 없다. 즉 함수에 들어가야 할 값이 안 들어가고 None이 들어가서 None이 나오는 경우, 우리가 의도한 상황이 아니지만 아무튼 에러는 안 난다. 이런 경우를 위해, 사용자 정의 에러를 사용하자.
from Slackbot import send_slack_message
class LoginError(Exception):
def __init__(self, target_name):
self.msg = '{target} 로그인 양식이 맞지 않습니다.'.format(target=target_name)
send_slack_message(self.msg)
def __str__(self):
return self.msg
class DBError(Exception):
def __init__(self, name, length, error):
self.msg = '{name} 에 대한 {len} 행의 데이터 입력 작업 중 오류가 발생했습니다.\n{error}'\
.format(name=name, error=error, len=length)
send_slack_message(self.msg)
def __str__(self):
return self.msg
코드 내에서 값의 유효성을 검증하는 부분을 추가하고, 유효하지 않을 경우 위와 같은 에러들을 raise 한다. 이 에러들은 raise 됨과 동시에 __init__ 에 의해 슬랙으로 에러 내용에 대해 정해진 양식의 메세지를 보내게 된다. 나는 실제 코드에선 Slack API가 작동하지 않을 것을 대비하여, 위의 코드에선 표시하지 않았지만 logging 모듈을 이용해 로컬 파일로 에러 로그를 작성하는 부분도 매 에러마다 추가해 두었다.
이외에도, 메세지는 보내되 크롤링은 그대로 진행해야 하는 경우도 있다. 1000개 중 하나만 오류가 난다면, 그 하나 때문에 크롤링이 완전히 중단되는 것보단 999개는 진행하고 1개는 나중에 처리하는 것이 합리적일 것이다. 그런 경우에도 간단히 이런 식으로 작성하면 될 것이다.
for name in name_list:
try:
crawl_something(name)
except:
send_slack_message('크롤링 중 {name} 를 처리하는 데 오류가 발생했습니다.'.format(name=name))
개인적으론 이 방식은 항목 하나라도 크롤링이 안되면 치명적이거나, 데이터 수가 매우 적은 경우를 제외하곤 추천하지 않는다. 천개짜리 name_list를 크롤링을 진행하는데 모두 오류가 나서 천 개의 메세지가 왔다고 가정하면... 끔찍하다. 차라리 실패한 갯수(except 블록이 실행된 횟수)를 카운팅해서 그 갯수를 보내주는 게 합리적일 것이다. 내 경우엔 일단 몇 개 정도는 당장 크롤링에 실패해도 서비스에 큰 지장은 없어서, except 블록에서 해당 에러를 로그 파일에 기록만 하도록 작성해 두었다.
5. 주의사항
위의 방법은 오류가 났다는 걸 능동적으로 알려주기만 할 뿐, 절대 오류를 해결해 주는 과정이 아님을 명심하자. 따라서 위에서는 가독성을 위해 생략했지만 문제 원인 파악과 해결을 위해선 logging 등의 기본적인 로그 작성은 필수다. 그리고, 유효성 검증을 적절하게 할 수 있도록 코드를 짜는 것 역시 중요하다.
현재 모 스타트업 기업에서 인턴을 하고 있다. 이곳에서, 기업들의 각종 데이터를 지정해둔 사이트들에서 크롤링해서 사용자에게 보여 주는 웹 서비스를 제작하고 있다. 중요한 건, 크롤링에 필요한 정보들이 수시로 변해서, 이 정보를 유동적으로 수정하고, 삭제하고, 지정할 수 있어야 했다. 처음에는 데이터베이스를 통해 이 정보를 취급하려고 했었다.
하지만, 이렇게 하기엔 문제가 있었다.
1. 이 서비스가 운영될 환경엔 전문 개발자가 없다. 따라서 DB에 대한 지식이 없는 관리자가 쉽게 데이터에 접근하고 수정할 수 있어야 하고, 그런 의미에서 DBMS를 통해 접속해서 데이터를 관리하는 건 부적절하다.
2. 그럼, 미리 데이터에 대한 질의나 수정 등 가능한 명령사항들을 래핑해서 일반적인 관리자들(DB에 대한 지식이 없는)이 이용 가능한 서비스로 만들 수도 있다. 하지만, 이 방법은 서비스의 규모나 가용 자원에 비해 너무 큰 작업이라고 생각했다.
이러한 사유로 DB를 사용하는 건 포기했다. 대신, 나는 다른 점을 주목했다.
1. 여러 가지 정보를 크롤링하는데, 그 중 가장 자주 일어나는 크롤링도 겨우 일 1회이다. 데이터 특성상 실시간으로 모을 필요는 없었다.
2. 기업의 정보는 생각보다 자주 바뀐다. 따라서 수정 작업이 빈번할 것이다. 또한, 단순히 크롤링을 위한 URL 데이터 뿐만 아니라, 기업에 대한 다른 데이터들도 저장하고 있었고, 이 데이터들은 정해진 형식이 있는 경우가 많다.
그래서, 나는 마땅한 대안을 찾다가 구글 스프레드시트를 주목했고, 읽기/쓰기 관련 API도 있다는 걸 알게 되고 데이터 저장을 위해 구글 스프레드시트를 사용하기로 결정했다.
혹시 오해할까봐 미리 적자면, '크롤링 할 대상에 대한 정보'를 구글 스프레드시트에 저장하는 것이고, '크롤링 한 결과'는 최소 수만 단위니까 당연히 DB에 저장했다. 구글 스프레드시트 입출력이 당연히 DBMS보다는 CRUD 관련 성능이 좋지 않다. 당장 사내에서 사용하는 시트 15개 X 시트당 약 5천행씩 존재하는 스프레드시트도 열 때마다 로딩을 몇초씩 기다려야 한다. 그러니까, 아래 방법은 데이터가 수백~수천 개 단위로, 비교적 크지 않을 떄만 활용할 수 있는 방법이다.
1. 스프레드시트 준비
이 부분은 따로 설명이 필요 없을 것 같다. 다만, 공개 데이터가 아니니까 당연히 비공개 스프레드시트로 하고 권한도 적절히 설정한다. 이 부분이 스프레드시트를 사용할 때 큰 장점중 하나라고 생각한다. 사용자에게 수정/열람/공개 권한 등을 손쉽게 설정할 수 있다.
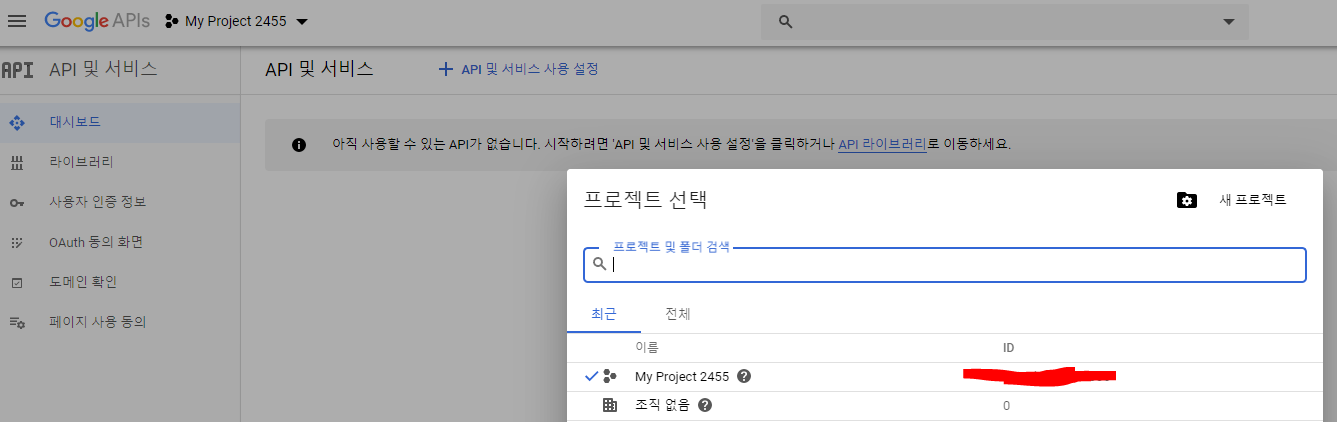
나는 현재 프로젝트가 하나 있기에, 지금 보이는 화면과 조금 다를텐데, 맨 위의 google APIs 옆에 아마 '프로젝트 없음'으로 뜰 것이다. 그걸 누르면 사진과 같이 프로젝트 선택이 뜨는데, 나는 만들어 뒀던 게 있어서 기존 프로젝트가 뜨지만, 아마 아무 것도 없을 것이다. 이제 새 프로젝트를 눌러서 프로젝트를 만들면 된다. 이 이후엔 읽어보고 특별한 사항이 없다 싶으면 예스맨 하면 된다.
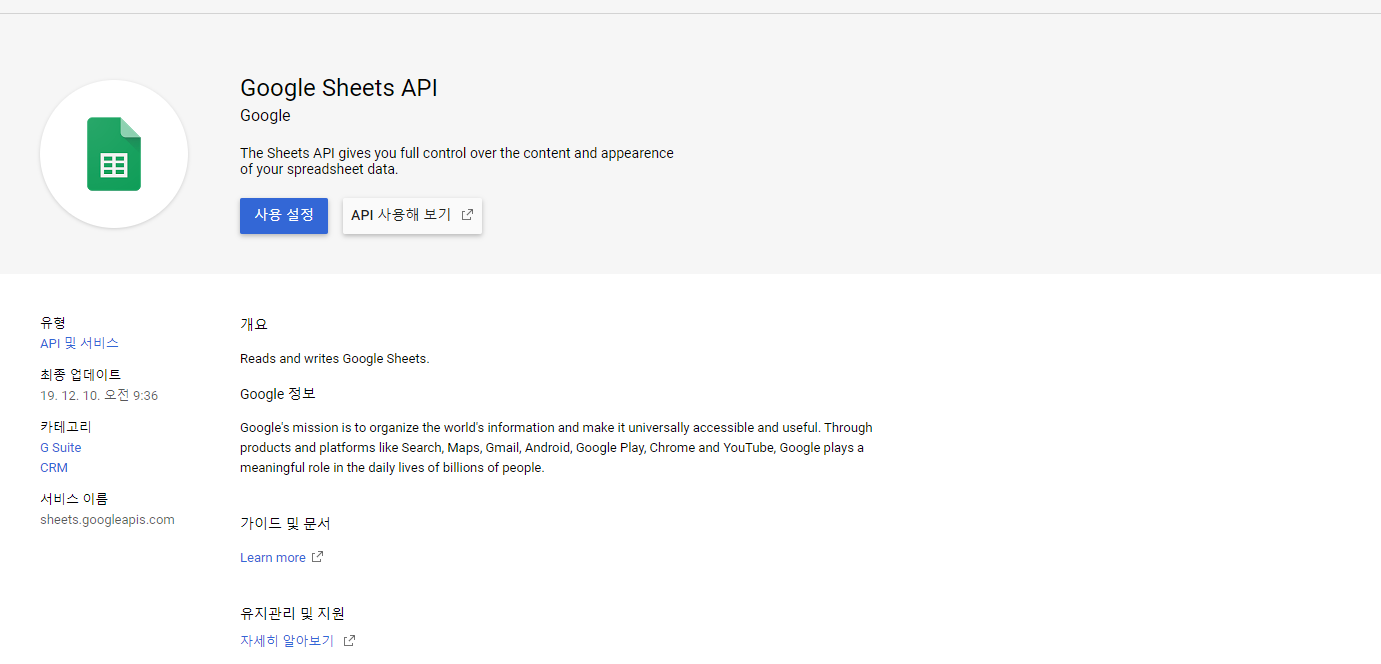
이제 프로젝트가 만들어졌고, 구글 스프레드시트 API를 사용하도록 설정해야 한다. 하라는 대로 API 및 서비스 사용 설정을 누르자. 그러면 크롬 웹스토어랑 비슷한 화면이 뜰 텐데 검색창에 sheet만 쳐도 아래와 같은 API가 나올 것이다.
사용 설정 버튼을 누르면 된다.
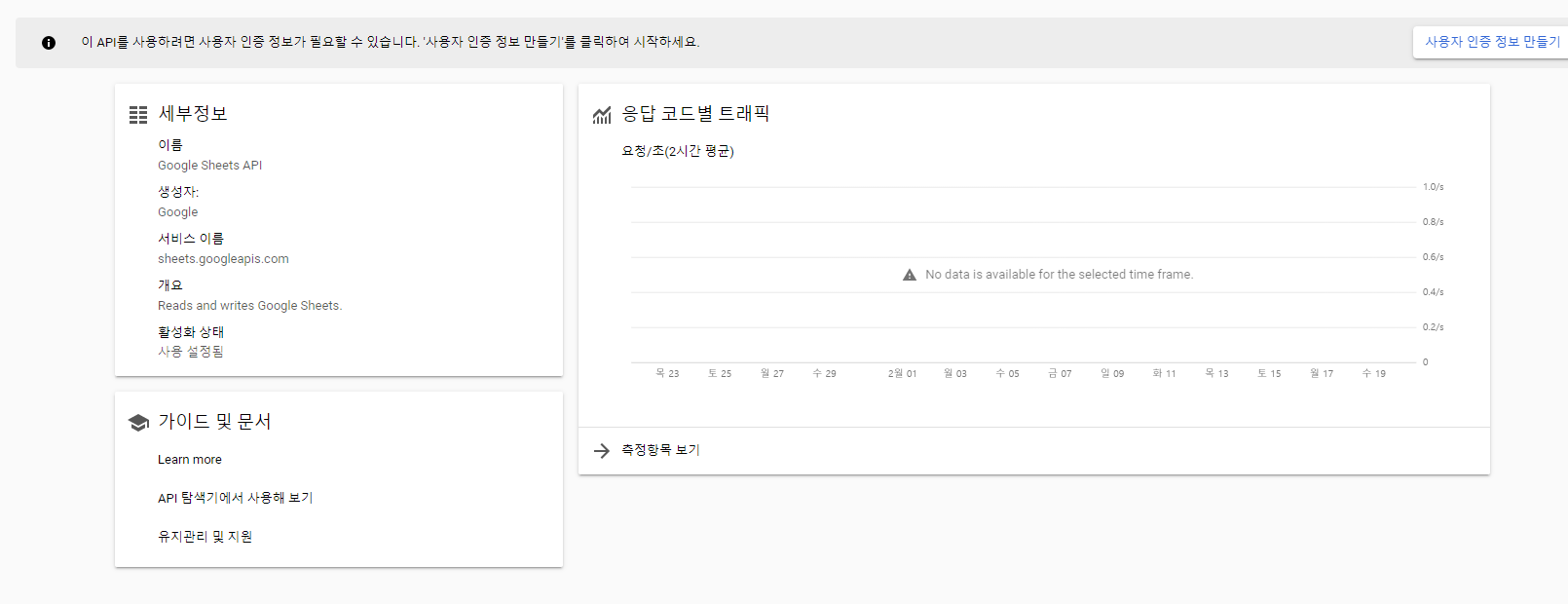
그러면 이 화면이 뜰 텐데, 아직 이 상태론 사용할 수 없다. 내가 누구인지 확인하기 위해 사용자 인증 정보를 만들어야 한다. 친절하게 만들라고 위에 버튼까지 띄워줬으니 만들러 가자.
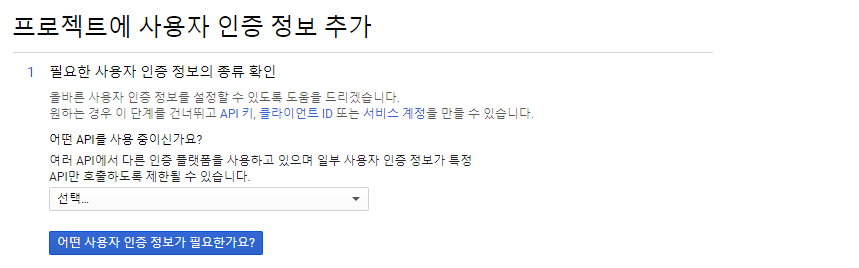
다음과 같은 화면이 뜰 텐데, 내가 썼던 방법을 소개하자면 나머지는 무시하고 위에서 '서비스 계정' 링크를 클릭한다.
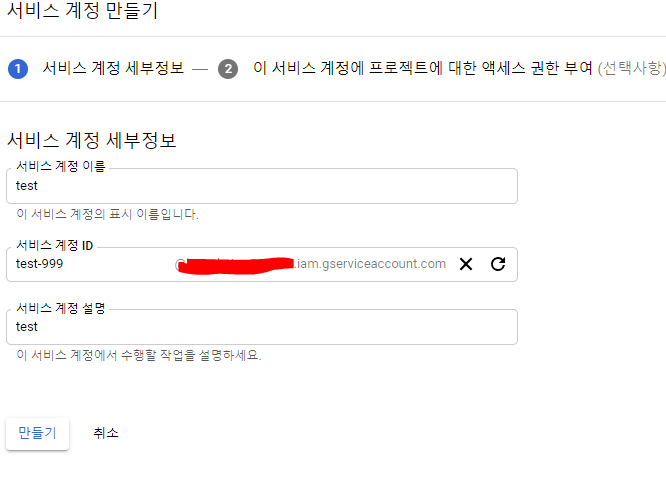
서비스 계정이 당연히 없을 것이다. '서비스 계정 만들기'를 클릭한다.
원하는 대로 서비스 계정 이름과 설명을 넣는다. ID는 자동으로 만들어진다.
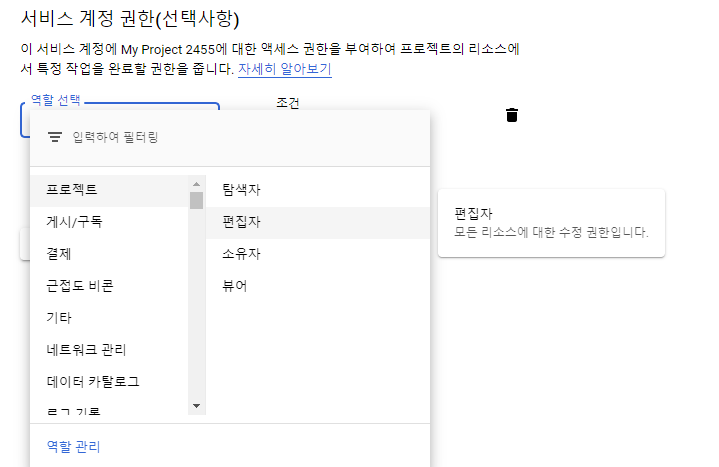
계정 권한은 다음과 같이 준다. '프로젝트-편집자'를 택했다. 사실 이 부분이 효과가 있는지는 모르겠는데, 혹시 몰라서 일단 줬다. 읽기 권한만 필요하면 뷰어만 줘도 될 것이다. (요 부분은 정확히 아시는분이 있으면 댓글 부탁드리겠습니다..)
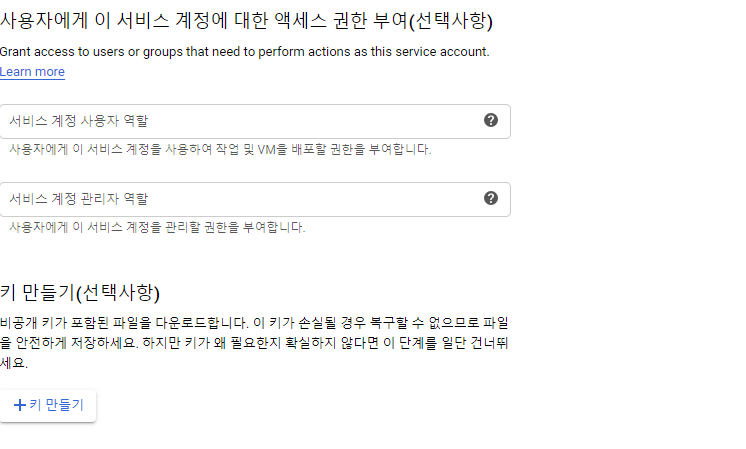
마지막으로 밑의 '키 만들기'를 누른다. JSON 형식으로 저장하면 된다. 이 키를 이용하여, 스프레드시트에 엑세스 할 것이다. 매우 중요한 파일이고 복구가 되지 않으므로 분실하지 않도록 함은 물론이고, 유출되지도 않아야 한다. 그래서 git을 사용해 관리할 땐, private 레포가 아니라면 꼭 이 파일은 ignore 해주자. 처음 생성하면 이름이 매우 길고 쓰기 힘드므로 적당히 UserKey.json 정도의 이름으로 바꿔주자.
마지막으로, 스프레드시트에 해당 서비스 계정의 이메일을 스프레드시트에 공유 설정하자. 권한은 해당 봇이 사용할 만큼 주면 된다. 해당 이메일은 서비스 계정 탭에서도 볼 수 있고, 잘 모르겠다면 방금 받은 json 파일의 'client-email' 항목에 있다.
이제 사용 준비가 완료되었다.
import gspread, os
from oauth2client.service_account import ServiceAccountCredentials
# 구글 API 사용을 위한 상수들
scope = ['https://spreadsheets.google.com/feeds',
'https://www.googleapis.com/auth/drive']
key_file_name = 'UserKey.json' # 아까 받은 json 인증키 파일 경로가 들어가면 됨.
credentials = ServiceAccountCredentials.from_json_keyfile_name(key_file_name, scope)
spreadsheet = gspread.authorize(credentials).open("<스프레드시트 이름>")
pip install gspread, oauth2client 를 통해 필요한 라이브러리를 설치한다.
이제 spreadsheet를 통해 원하는 대로 조작하면 된다.
3. API 활용하기
스프레드시트 API에 대해서는 구글 API 문서나 다른 블로거분들의 훌륭한 글이 많아서 따로 언급하진 않지만, 사용에 주의사항이 있다.
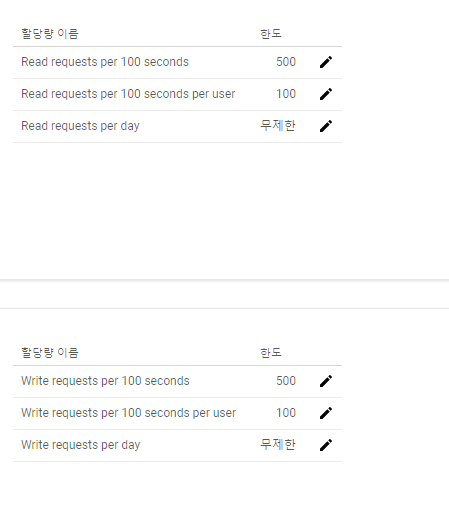
구글 Sheet API 무료 이용 한도이다. 기본적으로는 무제한이지만, 개인당 매 100초당 100회, 즉 초당 1개씩꼴의 요청만 보낼 수 있다. 즉, loop문 속에서 셀 하나씩 가져오는 식으로 코딩하면 바로 한도에 걸린다. 따라서, 다음과 같은 식으로 코딩해야 한다.
worksheet = spreadsheet.worksheet('<해당 시트 이름>')
product_url_list = worksheet.col_values(3)
product_code_list = worksheet.col_values(4)
product_url_list = product_url_list[2:-1] # 필요한 만큼 가공
product_code_list = product_code_list[2:-1] # 필요한 만큼 가공
return list(zip(product_url_list, product_code_list))
내가 사용했던 시트의 경우 단순화하면 이런 내용이었다.
데이터 목록
코드
바코드
81048
810483
82069
820697
...
...
합계 데이터 행
나는 코드와 바코드 데이터만 필요하고, 데이터 목록이나 합계 같은건 필요없었다. col_values(n) 같은 경우엔 해당하는 n열의 데이터를 모두 가져온다. 따라서 요청 한번으로 해당 열의 정보를 모두 가져오고, slicing을 통해 필요없는 데이터를 쳐냈다. 위의 경우엔 앞의 2행과 마지막 1행이 필요가 없으니 [2:-1] 을 통해 간단하게 가공했다. 지금 같은 경우는 간단한 경우고, 복잡한 처리가 필요할 땐 slicing하는 부분에 함수를 각각 따로 만들어서 처리하는 부분을 만들면 된다. 마지막엔 열 단위로 나눈 데이터를 다시 묶었다. 위의 경우엔 [('81048', '810483'), ('82069','820697'), ...] 과 같은 식으로 반환될 것이다.
4. 스프레드시트 사용의 장점 및 단점
위에서도 언급했다시피 데이터 수정과 열람, 삭제가 자유로움은 물론, 데이터 형식을 강제하여 규칙성을 유지할 수 있고, 필요한 최소한의 열만을 입력할 수 있다. 한 가지 내가 겪은 사례를 들자면, 나는 어떤 열에 숫자가 들어가되, 무조건 6자리로 들어가도록 해야 한다. 13이 들어가도 000013 이런식으로 들어가야 한다. 이것을 스프레드시트에서 서식 -> 숫자 -> 추가 형식에서 직접 지정을 했다.
위와 같이 지정하면 그냥 13을 입력해도 000013 과 같은 식으로 자동으로 0을 채워준다.
엑셀 함수 역시 활용할 수 있는데, 예를 들어 이 함수를 통해 해당 셀을 참고하여, 옆 셀이 비었으면 '비상장', 빈 셀이 아니라면 '상장사'를 자동으로 입력한다. 이런 식으로 함수를 활용하면 사용자가 직접 타이핑할 데이터를 줄일 수 있다. 사용자의 부담이 줄어듬은 물론이고, 예기치 못한 오타 역시 방지할 수 있다. 이외에도 특정 열에 중복을 허용하지 않도록 함으로서, 기본 키의 역할을 하도록 할 수도 있다.
다만, 이러한 스프레드시트를 통한 DB의 대체는, 데이터 읽기가 겨우 일 1회만 일어날 정도로 드물고, 데이터의 양이 수천 행 정도로 비교적 적었기에 가능했다. 실제로 데이터의 실시간 반영에 대해서도 많이 고민했는데, 결국 스프레드시트의 한계를 인정하고, 새벽 시간에만 데이터를 한꺼번에 받아와서 읽도록 했다.
최종적으로 완성한 시스템의 구조는, 스프레드시트의 데이터를 새벽 2시에 한꺼번에 읽어와서 서버의 DB에 기존 테이블을 삭제한 후 새로 받은 데이터를 넣고(이 과정이 행 500개 기준으로 10초 조금 안되게 걸린다.), 그 데이터를 기반으로 크롤링을 하도록 했다. 기존 테이블을 삭제하는 이유는, 엑셀에서 어떤 데이터가 변경되거나 삭제되었는지 아는 방법이 까다롭고, 매 행을 대조하는 식으로 억지로 구현할 바에는 그냥 매번 데이터를 새로 받아 쓰는 게 차라리 더 편했기 때문이다. 큰 데이터에 적합하지 않은 이유는 이러한 까닭도 있다.
마지막으로, 사용자가 엑셀에 대해 잘 모르면 효율이 떨어질 것이다. 함수나 서식 지정 같은 요소를 모르면 위처럼 데이터의 형식성을 강제할 수 없고, 결국 타이핑하는 사람에게 맡겨야 할 수밖에 없으니..
5. 결론
사실 처음 이 프로젝트에 대해 들었을 땐 이런 방법을 쓰리라곤 상상도 못했다. 사실 이 방법이 다루는 데이터가 많아야 수만~수십만 개 수준인 소규모 프로젝트라 가능했겠지만, 그래도 꽤나 재미있는 발상으로 극복해 낸 것 같다. 그래도 스프레드시트와 DB를 동시에 사용하면서, DB의 장점과 단점을 동시에 경험해 볼 수 있는 기회였다.