올해부터 모 대기업 계열 SI회사에 입사해서 다니고 있는데, 그 때까지의 과정을 간단하게 풀어보고자 한다. 내가 하고 싶은 말도 있고, 나한테는 나중에 추억회상용으로 읽기 좋을거 같고, 몇몇 분들에겐 재밌는 읽을거리이지 않을까 싶다.
2021년 초(~5월)
코로나가 여전히 맹위를 떨치던 그 때부터 나는 취업준비를 하기 시작했다. 사실 졸업까진 꽤 시간이 남았고 무엇보다 아직 취준 시작이라는 느낌에 크게 부담은 없었다. 고등학교 1학년때 누구나 SKY를 노리듯이, 나도 이 때는 한창 유명하던 네카라쿠배에만 관심이 있었다. 그래서 다른 기업들보단 네카라에만 지원했다. 무엇보다, 이들 기업들은 서류전형의 중요성이 매우 낮아 코딩테스트까진 무조건 갈 수 있기 때문에, 코딩테스트를 경험할 수 있다는 점이 큰 메리트가 있었다.
사실 그때는 알고리즘 자체를 몇문제 풀지도 않았고, 공부도 체계적으로 하는 것과는 거리가 멀었다. 그래서, 가서 풀어도 4문제중에 한문제 풀면 다행이다 생각할 정도로 결과는 항상 처참했고 한번도 면접까지 뚫어본 적이 없다. 하지만 결과는 크게 상관 없었다. 지금의 내 실력을 확인하는 선에서, 참가에 의의를 두는 올림픽 정신으로, 실전 감을 잡는 모의고사 용도로 시험을 봤던 게 사실이다. 다행히 각 계열사마다 인턴이니 뭐니 해서 은근 시험을 볼 기회가 많았어서 꽤 많은 시험 경험, 다양한 플랫폼을 경험해 봤다.
2021년 중(5월~8월)
그래도 이쯤 되니까 코딩 테스트가 몇개쯤은 뚫리기 시작했다. 이맘때쯤 한 면접을 3개쯤 봤다. 나는 대학도 정시로 왔고, 특별한 다른 대외활동을 한 적도 없어서 공군 면접과 알바 면접 말곤 면접 경험이 없었다. 그래서 처음 면접 간 회사에서 간단한 자기소개 해보라고 했을때, 따로 준비한게 없어서 어버버하며 임기응변으로 대답했던 기억이 난다.;; 물론 여기서 조금 데이고 나서 그 뒤의 면접들은 자기소개 멘트를 외워가며 좀 더 제대로 준비했다.
면접봤던 기업 중, 100명 규모의 스타트업 회사에 면접에 합격했다. 그래서 여름방학 두 달 동안 인턴으로 일했다. 솔직히 기대했던 거보다 엄청 특별한 일을 하지도 않았고, 인턴이다 보니 따로 실무를 경험한 건 아니다. 그래도, 알바나 개인 프로젝트보다 훨씬 제대로 된 사회경험 및 개발 프로세스를 체험할 수 있어서, 의미있고 값진 시간이었다.
이후, 여기서 정규직 전환을 제안받았다. 기술 스택, 회사에 대한 인상이나 업무 프로세스, 일하는 사람들은 매우 괜찮았기에 정규직으로 일하는 것도 긍정적으로 생각했지만, 내 생각보다 적은 규모의 연봉이 발목을 잡았다. 네카라쿠배 이런 기업들에는 당연히 못 미칠 거로 예상했지만, 내 생각보다 제안받은 금액이 작아 조금 당황스러웠다.
나는 신입이다보니 업계의 평균 연봉같은건 당연히 몰랐다. 그래서 이 때부터 주변에 수소문을 하며 의견을 물었다. 확인해 보니 일반적인 중소기업보다는 높은 금액을 제시받은건 맞았다. 그래서, 가장 먼저 생각한 건 일단 들어간 후, 중고신입으로 서비스 회사에 이직을 준비하는 것이었다. 하지만, 일을 해보니까 집에 가면 거의 피곤해서 항상 뻗는 일이 다반사였다. 인턴이라 야근이 하나도 없었는데도 말이다. 이런 경험으로 봤을 때, 정규직으로 일하면 낮에 일하고 밤에 따로 이직준비를 하는 게 쉽지 않다는 건 명백했다.
그래서 생각한 다른 방법, 퇴직후 재취준 역시 선뜻 고르기 어려웠다. 내가 다시 취업준비를 해서 여기보다 좋은 자리에 갈 수 있을까? 다시 말해, 내가 정말 여기보다 좋은 자리에 갈 수 있는 실력이 있는가? 그리고, 취업준비를 하면 당연히 그 동안 백수로 지내는 건데, 내가 나이가 적은 편도 아닌데 취업이 오래 걸린다면 그 동안 커리어에 손해를 보는 게 아닌가? 그냥 여기서 1년이라도 경력 쌓고 중고신입으로 들어가는게 쌩신입보다 훨씬 편하지 않을까? 등등.. 많은 의문이 들었고 나는 여기서 어떤 질문에도 편하게 답을 할 수 없었다.
그래서 정규직 제안 이후 굉장히 많이 고민했다. 주변에 자문도 구하고 혼자서도 고민하고 인터넷도 찾아 보며, 며칠동안 정말 고민을 많이 했다. 부모님께도 여쭤봤는데 내가 원하는 대로 하라고 말씀해 주셨다. 하루에도 몇 번이나 마음이 바뀌었다. 아마 올해 했던 고민중에서 가장 큰 고민이었을 건데, 재미있게도 내가 대입 때 했던 고민이랑 비슷했다.
나는 고3때 수능을 좀 망쳤어서, 기대에 미치지 못하는 성적이 나왔다. 그래서, 반수를 할 생각으로 성적에 맞춰 대학에 지원했다. 그런데, 등록금 고지서로 한 400만원 박혀서 오니까 정신이 확 들었다. 이 돈이면 재수학원에 드는 돈이랑 비슷한데, 어차피 반수로 탈출할 거면 그냥 이 돈을 재수학원에 넣는게 훨씬 돈과 시간 절약에 낫지 않을까? 라는 생각이 확 들었다. 물론 반수가 아니라 쌩 재수라는게, 돌아갈 곳이 없는 거니까 리스크도 당연히 크다. 하지만, 그냥 반수라는 애매한 입장에서 다시 공부를 시작한다면 이도 저도 아니게 될 것 같았고, 할 거면 제대로 하는게 나을 것 같았다. 그래 결국 대학 등록을 포기하고 재수학원에 등록했었다. 내가 현역때 잘못했던 점을 피드백 하면서 악착같이 공부했고, 성적을 올려서 결과적으로 이 때는 성공했다. 여담으로, 이 재수 얘기 자소서에 가끔 쓰는데... 인사담당자들은 이런 얘기 식상해서 별로 안 좋아하는 거 같다^^;
그리고, 주변인들한테 조언을 구하다가 들은 한 마디가 기억에 남았다. "나의 초봉이, 회사에서 평가한 내 가치이다." 즉 나는 딱 그 정도 금액의 사람이라고 평가된 것이다. 이 얘기를 들으니까, 어느 정도 오기가 생겼다. 나는 정말 이 정도 능력만 가진 건가? 그래서, 나는 내가 좀더 능력 있는 사람이라고 증명하고 싶어졌다. 지금 제시받은 금액도 작진 않지만, 나는 이거보다 더 받을 가치가 있는 사람이다라고 생각했다. 그리고 나는 이미 한번 비슷한 상황에서, 선택을 했던 경험이 있다.
그래서... 취업까지의 일대기를 다룬 이 글은 계속된다.
2021년 말(9월~12월)
아침에 출근 안하고 푹 자니까 기분이 좋았다. 역시 사람은 이불 밖에서는 살기 힘들다. 그래도 취준은 해야 하니까 이제 다른 의미로 바쁘다. 학교는 막학기라 교양 한과목만 등록해놓고 이것도 비대면이니 사실상 백수나 다름없었다. 이제는 본격적으로 취준하면서, 유명 서비스 기업 뿐 아니라 대기업 SI사들도 찾아 보면서 원서 뿌리고 다녔다. 마침 하반기 공채시즌이라 꽤 많은 공고가 떴다. 네카라도 전부 공채도 떴다.
코테보고, 자소서쓰고 하니까 금방 금방 시간이 갔다. 생각보다 자소서 문항이 비슷한게 많아서, 적당히 문항 보고 예전에 작성한 답변 붙여넣고 다듬는 식으로 작업했다. 나름 코테도 합격한 경험 있고, 개발 프로젝트 경험도 몇개 있어서 경험 소개하는 데에는 큰 문제가 없었다. 몇몇 기업에 면접까지는 가게 되었다. 특히 중간에 카카오 공채를 봤는데, 2차 코테까지 뚫으면서 내 알고리즘 능력은 문제 없다고 확신하면서 자신감도 잠시나마 가졌었다.
하지만, 생각보다 벽은 높았다. 뉴스는 요새 개발자 모자라서 그냥 대학만 졸업하면 아무 데서나 모셔간다는데, 막상 원서 넣고 다니다 보니까 전혀 체감 안됐다. 한 20개 이상 기업에 원서를 넣어 봤는데, 당장 서류탈락도 꽤 많았고 인적성 탈락, 코테 탈락 등 많은 탈락을 맛 보았다. "안타깝게도 다음 전형에 귀하를 모시지 못하게 되었습니다"가 아마 이 기간동안 가장 많이 본 문장이 아닐까 싶다.
면접 탈락도 몇번 있었는데 면접 탈락은 받을 때마다 특히 데미지가 컸다. 취업으로 향하는 마지막 관문이고, 여기까지 오는데도 서류나 코테, 면접 준비 등 소모된 에너지도 많아서, 떨어지면 반작용도 큰 거 같다. 특히, 스스로도 잘 봤다고 생각하고 면접관한테 개발 경험이 풍부하신 것 같다고 칭찬도 받았던 모 면접에서 탈락 통보 받고 나서, 심리적으로 충격이 컸던 것 같다. 이 탈락 통보 이후로 썼던 원서들은 멘탈 나가서 그냥 대충 썼고 전부 서류탈락 했었다 ㅎㅎ...
11월 말쯤 되면서 몇개 기업의 전형이 남아있지만 하반기 공채가 대부분 정리되었고, 나는 여전히 대학교에 간판을 걸어논 백수였다. 유명 기업에 입사한 내 주변인들이 정말 대단했던 거라는 생각도 들었고, 올해에는 취업을 못할 거 같다는 생각이 확실히 들었다. 부모님도 괜찮다고 하셨고 나도 취준생 생활을 시작한지 반년이긴 한데, 이미 내 멘탈은 랭크 게임에서 10연패쯤 한 걸레짝이 되어 있었다. 내가 게임에선 화나도 욕 거의 안해서 멘탈은 꽤 괜찮은 줄 알았는데, 아니었다 보다 ㅎㅎ....
특히, 나름 스스로의 실력에 자신감이 있어서 이전의 정규직 제안도 거절했던 거기에, 상황을 받아들이기 힘들었다. 이 기간까지 백수라는 건 아직 내가 지원했던 유수의 기업들에 들어가기엔 실력이 모자라다는 사실이니까. 마치, 쌩재수 시도했는데 재수도 실패해서, 현실을 인정하고 성적에 맞춰 대학을 갈지 삼수를 할지 결정하는 심정이었다. 싸피나 부트캠프라도 들어가야 하나? 라는 고민도 진지하게 해봤다. 비참...까지는 아니지만 그냥 나쁜 의미로 별 생각이 안 들었다. 내년에는 조금 더 낮은 기업까지 노려봐야 겠다는 생각도 확실히 했다.
12월 중순부터는 한 두세개 빼곤 거의 다 끝나서 사실상 거의 포기 상태로, 올해는 그냥 쉬자 하면서 다 때려치고 그냥 놀았다. 아무 기대 없이 시간만 때웠다. 그런데, 맨 마지막에 면접 봤던 기업이 있었는데, 결과 나왔다고 문자가 왔다. 별 생각 없이 이 회사의 불합격 멘트를 상상하며 회사 욕이나 하려고 채용페이지 들어갔는데, `안타깝게도` 대신 `축하합니다` ~ 어쩌구가 써있었다. 그래서 이 글이 여기서 끝나게 되었다.
하반기부터 본격적으로 취준했는데, 인터넷으로 정보 찾아보면서 느낀게 요새 개발자라는 직업이 핫한 거에 비해 정보가 엄청 부족하다는 느낌이 들었다. 잡코리아 잡플래닛 이런데 면접후기나 인적성후기(IT기업이라면 코테 후기를 보통 여기다 쓰는 것 같다)도 생각보다 쓸만한 정보가 없었다. 그래서 22년부터 준비하시는 분들에게 조금이나마 정보를 드리고자 따끈따끈한 21년 하반기 코테 대충 후기를 적고자 한다. 기업별로 쓰는것도 귀찮고 그냥 비슷한 회사들은 코테경향이 다 비슷해서 한꺼번에 써도 상관없을 것 같다.
솔직히 사람들이 뭘 궁금해 할지 모르겠어서 적당히 쓰고 궁금한거 있으면 댓글을 달아주시면 최대한 답해보겠습니다. 단, 똑같은 답변 두개 달긴 싫고 정보는 평등하게 공개되어야 한다는 생각이라, 비공개 댓글은 따로 답변하지 않을 예정이니 공개로 달아주세요.
** 나는 IT 취업 매니저도 아니고 인사담당자도 아니다. 시험 난이도도 당연히 회사 마음이다. 여기 내용은 참고만 하고 맹신하지 말고, 여기 내용 전적으로 믿지 말고(Ex: 이 회사 코테는 쉽다는데 이번엔 개어렵잖아!!) 반쯤 재미로 참고만 할 것!!! **
내가 지원했던 기업중에 지금 글을 쓸수 있을정도로 생각나는 데만 적었다. 편의상 A그룹, B그룹이라고 나눴다. 딱 보면 알겠지만 A그룹이 흔히 말하는 IT 서비스 기업들이고 B그룹이 흔히 말하는 대기업 IT 계열사(=거의 SI)들이다. 일단 코테 전에 서류전형이 있기는 하니... 서류전형에 대해서 우선 대충 느낀점은 아래와 같다.
A그룹 (IT 서비스 기업) - 서류
일단 IT 서비스 기업들은 대부분 서류는 그냥 자소서에다 욕이라도 박지 않는 이상 통과시켜준다. 당장 카카오를 비롯해서 몇몇 기업은 아예 시작할떈 자소서를 안 받고 면접 직전에 쓰도록 했다. 서류를 쓰는 기업들도 대부분 질문이 프로젝트 경험을 묻거나, 프로젝트에서 문제해결을 해 본 경험을 묻는 등, 쓰잘데기 없는 질문들 없이 진짜로 이 사람 개발역량만 평가하는 느낌이었다. 솔직히 이 회사들은 자소서 쓰면서 귀찮긴 해도 짜증나진 않았다. 왜냐하면 밑의 대기업 계열사들은 후....
B그룹 (대기업 계열사 = 거의 SI) - 서류
그냥 흔히 생각하는 자소서를 써야한다. 지원동기부터 시작해서, 문제해결경험, 협동을 한 경험, 직무경험, 역경을 극복한 경험 등 회사마다 묻는 것도 다양하다. 솔직히 쓰면서 ㅈ같았다. 물론 똑같은 내용을 수십 군데에다가 적당히 다르게 포장해서 쏴야 하니까 그런 것도 있긴 한데, 지원 동기를 비롯해서 뭔가 인사담당자 눈에 들도록 별거 아닌것도 잘 포장해야 하고 걍 왜 이짓을 해야하나 생각이 좀 많이 들었다. 이럴때마다 해당 공고의 다른 직무, 특히 영업 등 문과직무 자소서 형식을 보면 "저런 걸 사람이 어떻게 다 쓰지?" 하는 질문들만 가득해서 개발직무 자소서는 그래도 쓸만하구나 하면서 꾸역꾸역 썼다.
서류에서도 나름 유의미한 배수로 커트를 하는 편이다. 이건 경험담이라 잘 안다 ㅋ.... 물론 내가 자소서를 그렇게 신경써서 쓰는 타입이 아니라 그렇긴 한데... 아무튼 잘 써야 한다.
코테
단도직입적으로 말해서 코테 난이도는 A그룹>>>>>B그룹이다. 나는 음.. A그룹은 떨어진 코테도 반이 넘고 다 푼적이 없는데, B그룹 코테들은 2시간을 다 채워본 적이 없다. 그냥 빨리 풀고 시간 남아서 바로 나갔다. 특히 롯데정보통신 코테는 시작하고 30분동안 못나가는데 그 전에 다풀어서 프로그래머스 기능 구경하며서 시간 때웠던 기억이 난다.
딜리버리히어로 코리아 - 이건 공채는 아니었던 걸로 기억하고, 코딜리티라는 플랫폼을 썼었다. 문제가 죄다 영어라 아마 영어 못하면 힘들수 있는데, 코드포스에서 몇문제 풀어봤던 기억이 도움이 됐다. 문제보다도 영어가 일단 큰 장벽이었는데, 문제는 그래도 공부했으면 풀수 있는 정도로 나왔던걸로 기억한다. 통과했었음.
카카오 블라인드 2022 - 아주 흥미로웠고, 솔직히 코테가 재밌었다. 1차가 4시간동안 7문제 푸는건데, 당연히 어렵다. 프로그래머스에 기출문제가 다 있으니 보면 되고, 얘네들 특징이 비트마스크 좋아하고 설명충이다. ㄹㅇ 코딩하는 것보다 문제 제대로 이해하는게 더 어려울 정도로 설명이 길고 복잡한 문제가 많다. 설명이 짧으면 코딩이 무진장 어렵다.
2차는 알고리즘 문제가 아니라, 주어진 요구사항에 맞춰 자유롭게 코딩하는 문제다. 이게 생소할 수 있는데, 쉽게 말해 주어진 상황에서 여러가지 방법을 통해 어떻게 문제해결을 효과적으로 하는 지 평가하는 문제다. 이번에 나왔던 건 매칭 알고리즘 문제였는데, 매칭 관련해서 실력차에 따른 승패확률 등 상황을 전부 부여하고, 유저들의 MMR을 최대한 실제 실력지수에 맞게 추정하는 문제였다. 이것도 5시간인가 엄청 오래 봤는데 시간가는 줄 모르고 재밌게 풀었다. 실제 대회 환경에서는 스코어보드라고 해서 실시간으로 다른 사람들의 점수를 볼 수 있다. 이거 때문에 경쟁게임 하는 느낌이라 뭔가 의욕도 생기고 승부욕도 생겼다.
무엇보다, 절대 100점이 나올수 없는 구조로 정확성과 효율성 사이에서 타협을 하도록 만들어져 있어서, 절대적인 정답이 없다. 이것도 아마 프로그래머스에 올라올 건데 풀어보면 알겠지만 접근 방식이 정말 여러가지가 다 가능하다. 아마 대부분의 사람들은 롤이든 옵치든 MMR이 적용되는 게임을 해 봤을 테니 더욱 실생활(?)과 가까운 문제고, 실제로도 충분히 마주칠 수 있는 문제여서 흥미로웠다. 종료 30분전 기준으로 1000몇명 중 200몇등 했는데 통과함.
네이버 / 라인/ 네이버클라우드 - 셋 다 따로 신청받고 따로 코테하긴 했는데 다 떨어졌으니 묶어서 설명하자면, 걍 백준이나 프로그래머스 문제 잘 풀고 열심히 알고리즘을 준비해야 한다... 특히 여기는 문제도 어려운데 채점 결과도 안 알려주니까, 빠르고 정확하게 풀줄 알아야 한다. 사실 빠르기는 적당해도 되는데 정확하게 푸는게 ㄹㅇ 중요하다. 코테는 테스트케이스 20개중에 하나만 틀려도 0점이니까... 푼 문제들은 예시 테스트케이스는 다 통과했는데 실제 테스트케이스에서 많이 걸린 것 같다.
이베이 - 며칠전에 본거고, 솔직히 최합한 기업이 있어서 그냥 문제 구경만 해봤는데 카카오 3~4번 정도의 문제가 5개 있고 이걸 2시간 안에 풀라고 나왔다. 음... 5솔한 사람은 아마 백준 리더보드에서 볼수있지 않을까?
롯데정보통신 / CJ올리브네트웍스 / LG CNS / SKT 등등 B그룹들은 다 비슷해서 한꺼번에 설명하겠다.
코테 문제는 위에서 말한거처럼 서비스 기업들과 비교할 바가 안 된다. 그냥 내가 풀면서 든 느낌이 어땠냐면...
A그룹은 이 사람이 진짜 주어진 조건에서 이것저것 예외상황들을 모두 생각하며, 탐색, DP, 정렬 등 알고리즘 지식에 기반하여 상황에 맞는 최적의 알고리즘을 고안하여 문제를 해결할 수 있냐? 를 물어본다면,
B그룹은 주어진 조건에 맞춰서, 요구사항대로 정확히 구현할 수 있냐? 정도만 물어보는 느낌이다. 특별한 알고리즘이 필요 없이, 그냥 하라는 대로만 정확히 구현하면 따로 효율성 필요 없이 다 풀린다.
대신, 이 기업들은 코테와 더불어 전부 인(적)성검사도 본다.
롯데정보통신 - 인프라 직무는 알고리즘 문제를 2문제를 줬는데 20분만에 다 풀었다. 대신 네트워크 지식을 묻는 객/주관식 문제를 따로 풀었고, 인성검사도 진행했다. 네트워크 문제는 학부 네트워크 수업 내용 2/3, 하드웨어 비롯한 단순 지식문제 1/3정도로 나왔던 걸로 기억한다. 인성검사는 그냥 일관성 있게 착하게 잘 풀면 해결.
CJ 올리브네트웍스 - 여기 있는 기업들 중에선 코테가 그래도 좀 난이도 있었다. 사실 3문제 중에 2문제가 쉽고 마지막 3번째 문제가 BFS를 살짝 꼬아놓은 문제라 좀 어려웠다. 인성검사도 그냥 인성검사라 잘 풀면 된다.
LG CNS - 아... 여기부터 할말이 많다. 코테는 특별히 생각나는 문제 없이 잘 풀었다. 근데 여긴 인성과 더불어 적성검사도 본다. 흔히 타직무들 취준할때 나오는 그 적성검사다.
비대면으로 진행해서 컴퓨터에 프로그램 깔고 풀었는데, 문제 하나하나는 쉬운데 문제마다 1분씩만 투자해서 풀어야 했다. 그래서 모르는건 바로바로 넘기는 게 전략이다. 어차피 이건 만점이 목표인 시험이 아니니까... 이거땜에 도서관 가서 LG 인적성 책 빌려서 조금 풀어봤는데, 실제로 시험 보니까 비대면 시험 전환 이후 출제경향이 완전히 바뀌어서 문제 난이도가 차원이 다르니 별로 쓸모 없었다. 막 쌓기나무 보여주고 거기에 블럭 몇 개 들어갔나 세어야 하는 문제도 나오고, 거리속력시간 문제도 나오고 해서 중고등학교 다닐때 생각이 났다. 문제는 전혀 어렵지 않으니 걱정하지 않아도 된다. 중고등학교때 수학 포기하지만 않았으면 충분히 다 풀수 있는 문제들이다. 그거보단 시간관리랑 모르는 문제 나왔을때 바로 넘길수 있는 결단력이 중요하다.
아마 2022년쯤 되면 신경향 반영해서 책 새로 나올거 같으니 그거 참고하면 된다. 나는 사실상 그냥 가서 풀었고 통과했다. 따로 책까지는 살 필요 없을거 같다...라고 말해도 취준생 심리상 불안한게 정상이다. 나도 책사야 하나 진지하게 고민좀 했었으니까... 솔직히 개발자 취준할때 적성검사를 보는 기업 자체가 극소수라 책을 사기엔 좀 아깝고, 도서관에 구입 신청해서 빌려서 푸는거 추천한다.
SKT - 여기 코테는 난이도는 평이했는데 되게 실생활이 잘 접목된 문제가 나왔다. 마지막 문제로 오목의 승리조건을 구현하는 문제였고, 다른 문제 중에선 회사 주변 커피숍 브랜드 이름을 그대로 들고 나와서 웃겼던 기억이 난다.
인적성이 아주 ㅈㄹ같았는데, 적성이 많이 매웠다. 그 흔히 문과분들이 준비하는 책 사서 푸는 그런 유형들과 난이도로 나왔다. 이것도 비대면으로 컴퓨터로 봤는데, 사실 문제도 어려웠지만 따로 종이를 못쓰는 환경이고, 컴퓨터로만 그림 그리고 계산하고 모든 걸 해결해야 하는데 난 마우스로 뭘 그리는건 정말 못해서 고통스러웠다.
특히 N-back 문제라고 AI면접 경험자분들은 아는 그 게임도 나왔다. 연속적으로 비슷한 그림들 보여주고 이게 n번째 이전의 그림이랑 같은지/다른지 판별하는 문젠데, 유튜브 가서 풀어보면 알겠지만 연습 안하면 풀기 많이 어렵다. 솔직히 떨어졌으니 얘기하지만 이딴거 다신 풀고 싶지 않다. 아무튼 적성은 그냥 싹 조지고 나왔다.
그냥 적성검사를 준비하는 것 자체가 SW분야 취준생한텐 너무 계륵인거 같다. 내가 위에서 적성검사 욕을 좀 써놨지만 사실 수천명 지원자 중에서 사람 가리려면 당연히 변별력 있어야 하는건 이해한다. 그런데, SW분야는 타 직무의 적성검사를 거의 코테로 대체해놨고, 극히 일부 기업만 적성검사를 본다. 코테도 준비해야 하는데 적성검사도 준비한다? 취준생활을 연 단위로 하지 않는이상 솔직히 힘들 것 같다. 이런 맥락에서 LG CNS정도의 쉬운 적성검사는 돈아까우니 책은 사지 말라고 했었다. 선택은 본인 몫이다...
인터넷에 뒤져보면 python의 reduce 함수에 대해서는 많이 있는데, 정확한 명세를 알려 주는 글은 잘 없는 것 같아서 직접 정리해 본다.
reduce(func, iterable , (optional)value)
from functools import reduce
# 케이스 1
test_list = [20, 5, 4, 3]
result = reduce(lambda a, b: a - b, test_list)
print(result)
# 결과: 8
# 케이스 2
test_list = [20, 5, 4, 3]
result = reduce(lambda a, b: a - b, test_list, 100)
print(result)
# 결과: 68
func:
reduce 과정이 진행되면서 실행될 함수로, 람다 함수든 일반 함수든 상관없지만, func(a,b) 형태로 파라미터 두 개를 받아야 한다.
a는 reduce를 진행하면서 누적된 값, b는 iterable 객체에서 가져온 원소이다.
당연히 파라미터 순서가 상관 있으니, 유의해야 한다. 대부분의 인터넷 예시에선 +를 사용하여 이 점이 잘 드러나지 않아서, 일부러 -를 사용해 보았다. 만약 파라미터 순서가 바뀐다면...
from functools import reduce
test_list = [20, 5, 4, 3]
# 케이스 1에서 a-b가 b-a로 바뀐 상태
result = reduce(lambda a, b: b - a, test_list)
print(result)
# 3 - (4 - (5-20))
# 출력 : -16
iterable
list, tuple, .. 등등 순회 가능한 요소는 모두 가능하다.
value
위 케이스 1,2의 차이가 초기값의 유무이다. 이 값이 주어지지 않았다면 iterable 객체의 첫번째 원소를 초기값으로 사용하여, reduce 과정에서 맨 처음에 첫번쨰 원소와 두번째 원소에 대해 fucn을 실행한다. 위의 케이스 1에선 20 -5 가 첫번째로 수행되었다.
초기값이 주어지면, 맨 처음에 value와 첫번쨰 원소에 대해 fucn를 실행한다. 위의 케이스 2에선 100 -20이 첫번째로 수행되었다.
즉, 초기값 유무에 따라 func 함수의 실행 횟수가 1번 차이가 난다. 아래의 예시를 보면 이해가 빠를 것이다.
from functools import reduce
test_list = [20, 5, 4, 3]
def reduce_fun(a, b):
print("함수 실행")
return a - b
result = reduce(reduce_fun, test_list)
print(result)
result = reduce(reduce_fun, test_list, 100)
print(result)
""" 출력:
함수 실행
함수 실행
함수 실행
8
함수 실행
함수 실행
함수 실행
함수 실행
68
"""
reduce 코드 살펴보기
_initial_missing = object()
def reduce(function, sequence, initial=_initial_missing):
it = iter(sequence)
if initial is _initial_missing:
try:
value = next(it)
except StopIteration:
raise TypeError("reduce() of empty sequence with no initial value") from None
else:
value = initial
for element in it:
value = function(value, element)
return value
functools.py에 정의된 reduce 함수의 내용이다. 내용은 크게 어렵지 않으니 천천히 살펴보자. initial 파라미터의 유무에 따라 value=initial 또는 value =next(it)를 통해 시작값을 정의한다. 시작값이 주어지지 않았다면 이미 본격적인 reducing 과정 전에 원소를 하나 순회하므로, 순회 횟수에 차이가 생기는 것이다. 아래엔 value = function(value, element)를 통해 값을 계속 갱신한다. 이 부분을 통해 왜 fucntion의 파라미터 순서가 상관 있는지, 꼭 파라미터 2개만 들어가야 하는지 알 수 있을 것이다.
자세한 정보, 특히 복잡한 쿼리문에 대한 정보를 원한다면 이 사이트들을 방문하면 편할 것이다. 아래의 내용 역시 위 사이트를 대부분 참고하였다.
1. DynamoDB 기본
DynamoDB가 왜 필요하게 되었는가
간단하게, DynamoDB가 왜 세상에 나타났는지부터 살펴보자. noSQL류 데이터베이스를 사용하지 않고 RDB를 사용하던 시절, 아마존의 엔지니어들이 자사에서 데이터베이스를 활용하는 패턴을 분석했다. 놀랍게도 무려 90%의 연산이 JOIN을 사용하지 않았다. 또, 약 70%의 연산이 단순히 기본 키를 이용하여 하나의 행을 가져오는 key-value 형식의 연산이었다. JOIN은 매우 코스트가 큰 연산이라 JOIN을 피하기 위해, 한 마디로 성능을 위해 정규화를 포기하는 경우도 있었다. 이렇게 엔지니어들은 관계형 데이터베이스 모델의 필요성에 대해 의문을 가지게 되었다.
이와 더불어, 대부분의 RDB는 강한 일관성을 주요 특징으로 내세운다. 이 말은, 특정 연산이 실행된 이후, 모든 유저들이 해당 부분에 대해서 동일한 결과를 받아야 한다는 뜻이다. 이 점이 현실의 상황에선 어떤 문제를 갖는지 살펴보자. A는 서울에 살고, B는 브라질에 살고 있다. A가 트위터에 'hello'라는 게시물을 올렸다. RDB를 사용하는 상황이라면, A가 게시글을 올린 순간 트위터 본사가 있는 미국 서버 내 데이터베이스에 'hello'가 커밋되고, 모든 트위터 유저들은 A의 타임라인에 들어가면 'hello'가 보여야 한다. 하지만, 물리적인 거리를 고려하면 A가 글을 작성한 이후, 서울에서 미국까지 갔다가 브라질까지 가는 데 필연적으로 (컴퓨터의 세계에선) 적지 않은 시간이 소요된다. A는 글을 썼지만, B는 해당 글을 조회할 수 없어 일관성에 어긋나게 된다.
물론, 이를 해결하기 위한 방법이 있다. 서울과 브라질 각각에 데이터베이스 인스탄스를 두고, 서로 완전히 복제하도록 하는 것이다. 이 경우, 일관성을 유지하기 위해선 A가 작성한 글은 데이터베이스에 바로 커밋되지 않고, 우선 A의 글을 전 세계의 데이터베이스로 퍼뜨린 후, 동시에 커밋해야 한다. 'hello' 라는 글이 업로드됨과 동시에, 전 세계의 유저들이 저 글을 볼 수 있다. 하지만, 이 시나리오를 실현하려면 우선 여러 대의 데이터베이스를 한꺼번에 관리할 수 있는 복잡한 시스템이 필요하고, 무엇보다 A의 요청엔 불필요한 지연 시간이 생긴다. 일관성은 지켰지만, 이번엔 가용성에 문제가 생기게 된다.
이러한 문제를 해결하기 위해 역시 아마존의 엔지니어들이 고민한 결과, 강한 일관성은 지키지 않아도 된다는 결론이 나왔다. 정확히는, 은행 거래와 같이 신뢰성이 생명인 부분에선 강한 일관성이 중요하지만, 위의 트위터의 사례와 같은 대부분의 일상적 상황에선 일관성보단 가용성과 속도가 더 중요하다는 것이다. 즉, 트위터에 올린 글이 다른 사람들에게 몇 초 늦게 보여져도 크게 문제가 생기지 않는다는 점이다. 이러한 점들에서, 기본의 관계형 DB보다 일관성, 관계성을 약화하고 대신 가용성 및 확장성에 초점을 둔 DynamoDB가 탄생하게 되었다.
Table의 구조
각 테이블 안에는 item이라고 불리는 항목들이 있고, 각 항목 안에는 RDB의 column 같은 개념의 attribute(속성)들이 들어 있다. 위 그림에선 People이라는 테이블 안에 item 3개가 있고, 각 아이템 안에는 여러 가지 속성을 가지고 있다. noSQL이라는 특성상 정형화된 구조가 없기에, 각각의 아이템은 저마다 다른 구조를 가질 수 있다.
각 아이템들을 구분하는 용도로, partition key가 있다. 필수적으로 테이블에 존재해야 하며 흔히 말하는 기본 키에 해당하며, 해시 함수를 통해 각 아이템의 저장공간이 지정되며 서로 다른 값을 가져야 한다. 위의 예제에선 PersonID가 파티션 키이다. 또, 필수는 아니지만 sort key라는 테이블 내 아이템의 정렬에 사용되는 키가 있다. 이 파티션 키와 정렬 키가 합쳐서 복합 기본 키(composite primary key)로, 두 개의 속성을 합쳐서 기본 키처럼 사용할 수 있다. 이 경우, 기본 키와 정렬 키 중 하나만 달라도 서로 다른 아이템으로 인식이 될 수 있다.
또 키와 별개로 인덱스를 생성할 수 있는데, 두 가지의 인덱스가 있다. local secondary index(로컬 보조 인덱스)는 기존의 파티션 키와 함께, 지정했던 정렬 키 이외에 다른 속성을 정렬 키처럼 이용하여 테이블에 접근하고 싶을 때 사용할 수 있다.global secondary index(전역 보조 인덱스)는 아예 기존의 키와 관련없는, 새로운 구조의 키(단순 파티션 키or복합 키)를 사용하고 싶을 때 쓸 수 있다. 전역 보조 인덱스가 더 넓은 개념이라고 보면 된다.
우선, boto3.resource와 boto3.client를 불러왔다. 둘 다 AWS의 서비스를 이용하기 위한 SDK이다. 차이점이라면 resource는 client를 래핑한 고수준의 서비스이다. 따라서, client는 비교적 로우 레벨에 접근이 가능하며, resource를 이용하여 다룰 수 없는 부분을 위해 사용한다. 테이블을 부르는 건 resource.Table(테이블명)으로 간단하게 불러올 수 있지만, 처음 실행한 상태라면 아직 아무 테이블도 존재하지 않을 것이고, 따라서 맨 밑의 부분에선 오류가 뜰 것이다. 우선 테이블을 만들어 보자.
문법이 굉장히 복잡하다. 이걸 create_table에 파라미터로 그냥 박으면 가독성이 답이 없으므로 위처럼 일단 딕셔너리 형태의 변수로 뺀 후에 넣는게 제일 편할 것이다.
간단하게 스키마에 대해 설명하자면,
- TableName : 말 그대로 테이블 이름이다.
- KeySchema : 테이블에서 key로 사용할 속성들에 대해 정의해야 한다. KeyType은 'HASH'는 파티션 키, 'RANGE'는 소트 키를 나타낸다.
- AttributeDefinitions : 쉽게 말해 여기 스키마에서 언급된 키와 인덱스에 대해선 전부 여기 명시되어 있어야 한다. 키뿐만 아니라 인덱스를 쓴다면 인덱스에 명시된 속성들도 있어야 한다는 점에 유의해야 한다.
여기 쓰이는 type엔 S, N ,B 세가지가 있는데 각각 String, Number, Binary 이다. 각각의 속성에 맞춰서 넣으면 된다.
- LocalSecondaryIndexes : 위에서 언급한 로컬 보조 인덱스이다. 인덱스 이름과 키 schema를 입력한다. 위에서 봤듯이 로컬 보조 인덱스는 파티션 키를 그대로 사용하기에, 우선 기존 파티션 키를 그대로 쓰고 다음에 인덱스로 사용할 키를 정의한다. Projection은 인덱스로 복사할 속성 및 옵션을 정하는 부분이다.
GlobalSecondaryIndexes는 위의 로컬 보조 인덱스와 거의 유사하게 사용할수 있기에, 따로 언급하지 않았다.
- ProvisionedThroughput : 각각 읽기, 쓰기에 사용할 유닛(=동시에 처리 가능한 트랜잭션의 수)의 수를 정하는 옵션으로, 데이터베이스의 구조와는 관련이 없지만 트래픽에 따라 유연하게 조정할 수 있다.
이렇게 열심히 언급했는데, 솔직히 쓰면서도 좀 많이 복잡하다.
그냥 키-값 store로 사용하고자 한다면 간단하게 아래의 코드를 통해 테이블을 생성할 수 있다.
table.scan()을 통해 전체 테이블의 항목 및 아이템의 수를 위와 같이 가져올 수 있다... 인줄 알았는데 안 된다. AWS 문서에 따르면, 1MB 크기 내에서만 결과를 반환하기 때문에, 큰 데이터를 가져오려면 쿼리를 계속 불러서 페이지네이션처럼 처리해야 한다. 이는 count도 마찬가지라 정확한 테이블 내 아이템 개수를 반환한다고 보장하지 않는다.
from boto3.dynamodb.conditions import Key
table = resource.Table("TestTable")
query = {"KeyConditionExpression": Key("name").eq("키값")}
print(table.query(**query))
# 결과물은 위와 동일하게 table.query(**query)['Items']와 ['Count']로 각각 아이템과 아이템 수 조회 가능
Key나 Attr에 eq뿐만 아니라 lt, gt, between 등등 많은 조건을 붙일 수 있다.
scan과 query를 사용한 방법을 제시했는데, query는 key를 이용하여 결과를 조회하는 거라면, scan은 그냥 말 그대로 테이블 전체를 훑는 거라 큰 테이블에서 사용하면 심각한 성능 문제를 야기할 수 있다. 심지어 scan은 필터 조건을 걸어도 일단 싹 긁은 다음에 필터링 하는 방식이라, 큰 테이블에서 쓰기 힘들다. 그래서, 작은 테이블이 아닌 이상 가급적 query를 쓰는 게 좋다.
아이템을 수정하는 방식은 특이하다. 수정 대상인 키를 지정하고, UpdateExpression을 통해 자체적인 문법을 통해 업데이트 명령을 지정한다. 여기서 new_data는 임의로 정한 값으로, 변수명 앞에 콜론(:)을 붙여 내부적으로 사용하는 변수임을 나타낸다. 마지막으로, ExpressionAttributeValues를 통해 내부 변수가 어떤 값을 가지고 있는지 표현한다. 나는 새로 업데이트될 값으로 썡 문자열 'new_attttt'를 지정했는데, 값을 바꿀 속성인 att1이 인덱스나 키에 속하지 않은 이상, 당연히 여기엔 어떤 파이썬의 기본 오브젝트(숫자, 문자, 리스트, 딕셔너리 등)이 와도 괜찮다.
추가적인 파라미터인 ConditionExpression를 통해 WHERE절처럼 조건부 삭제를 할 수도 있다.
R과 U는 상세하게 설명했는데 나머지는 이렇게 한번에 설명해도 될 거 같다. 왜냐하면, 위에서 다룬 문법들을 그대로 활용하면 되기 때문이다. 예를 들어 조건부 삭제를 하고 싶으면 update의 조건부 업데이트와 똑같이 조건을 지정하면 된다. 나머지 명령들도 위에서 사용한 문법과 거의 유사하다.
get_item()은 단 하나의 아이템만 읽어 오는 함수로, 여러 개를 읽어 와야 할땐 위에서 본 scan()이나 query()를 사용하면 된다.
테이블 삭제는 워낙 간단해서 저 한줄이면 충분하다.
전체적으로 파이썬 문법보다는 aws cli를 활용하는 능력이 더 중요한 것 같다. 사실 ConditionExpression, FilterExpression과 같이 파라미터들이 이름이나 문법이나 무지하게 복잡한 이유가, 그냥 boto3 자체가 aws cli를 파이썬에서 활용할 수 있게 만든 라이브러리라, 거기서 쓰던 변수명이나 방식을 그대로 가져와서 그런 것 같다. 그래서, 어느정도 깊게 다루려면 python, boto3보다는 오히려 aws cli에 더 익숙해져야 할 것 같다.
일단 이론적으로는 이런 구조로 결제가 이루어진다. 눈에 띄는 특징은 카드정보가 우리의 웹 서버를 거치지 않고 다이렉트로 카드사 서버로 전달되는데, 이게 법적 제한으로 일부 카드사나 PG사 등을 제외하고는 카드정보를 저장할 수 없다. 그 외에는 가맹점 서버에서 PG 서버로 결제 요청을 전달하고, PG 서버에서는 카드사와 실제 결제를 수행하고, 그 결과(결제성공/실패)를 가맹점 서버에 돌려주는 구조이다. 그래서, 실제 결제 프로세스는 아래와 같이 이루어진다.
위의 그림과 사실 큰 차이 없다. 대신, 구매자 브라우저에서 전달되는 카드정보(카드번호, CVC 등)이 가맹점 서버에서는 알 수 없도록 전달된다는 사실만 기억하면 될 것이다. 위 그림에서, 우리는 3,4,7,8만 신경쓰면 되고 PG 서버로 데이터가 넘어간 이후 다시 응답을 받을 때까지는 신경쓸 필요가 없다.
PG사들도 결제 모듈을 모두 지원하고 있고, 개발자들에게 제공하고 있다. 그래서, 여기까지만 해도 결제에는 아무 문제 없다. 그렇지만 아임포트를 도입한다고 가정하자. 아임포트는 바로 가맹점 서버와 PG 서버의 사이에 있다. 그림판으로 조악하게나마 그림을 다시 그려보면 이렇게 될 것이다.
즉 아임포트의 도입을 통해, PG사와의 통신 과정도 래핑을 하게 된다. 그러면, 이제 이런 의문이 생길 것이다. 왜 굳이 아임포트가 중간에 들어가야 하는가? 바로 이게 결제에 아임포트를 사용해야 하는 이유가 될 것이다. 그래서 내가 생각한 이유들을 아래에 정리해 놓았다.
1. PG사와의 복잡한 연동과정
나는 처음으로 사용한 PG사가 KCP인데, 처음에는 아임포트 없이 직접 결제를 구현하고자 호기롭게 매뉴얼을 다운받아 열어봤다. 일단 메뉴얼도 수십 페이지인데, 그야말로 읽다가 정신이 나갈 것 같았다. 일단 서버에다가도 PG사와의 소켓 통신을 위한 모듈을 이것저것 깔고, 서버 설정도 만져야하고 뭐뭐 깔아야하고 할일이 수두룩했다. 주고받는 데이터도 양식이 복잡했다. 예제는 PHP랑 JSP밖에 없어서 별 도움도 안 됐다. 이러한 귀찮은 과정들을 미리 해 놓은 서버가 있어서, 내가 거기다가 결제에 필요한 정보만 보내면 알아서 다 해주는 서버가 있다면 어떨까? 그게 바로 아임포트 서버이다. 그냥 결제에만 신경쓸 수 있게 해 주는 것이다.
2. 복수 PG사 사용시 편리함
당장 배달의 민족만 봐도, 배달음식을 결제할 때 카카오페이, 스마일페이, 네이버페이, 신용카드 등 여러 가지 결제 방식을 지원한다. 카카오톡을 안 쓰는 사람은 거의 없지만 카카오페이를 안 쓰는 사람은 많듯이, 하나의 결제 방식으로 모든 고객들을 커버할 순 없다. 그래서 여러 개의 결제방식을 지원하는 게 중요한데, 당연히 PG사들마다 결제 모듈이 제각각이다. 즉 1번의 저 귀찮은 과정들을 전부 다 따로 해야 한다. 아임포트는 PG사와 상관없이 결제에 정형화된 API 형식을 사용한다. 그래서 가맹점 서버에서 결제 모듈을 재활용 하기 용이하다... 사실 용이함을 넘어 그냥 결제 파라미터 하나만 바꾸면 거의 모든 PG사에 돌려 쓸 수 있다.
2-2. 매출 관리의 용이함
이건 개발과는 크게 상관없는 내용이지만, 여러 개의 PG사를 운용할 경우 각 PG사마다 결제 내역이 있을 것이다. 이 결제 내역들을 아임포트 관리자 콘솔에서 한꺼번에 보고 관리할 수 있다.
3. 환불이 쉬움
이게 대체 장점이 맞나 하겠지만.... 개발자의 관점에서 내가 제일 사랑하는 기능이다.
아임포트 결제로그 페이지에서, 성공한 결제에는 취소하기 버튼이 생긴다. 이거 누르면 바로 환불이 된다. 결제 기능 테스트할때, 처음에는 돈 깨질거 각오하고 1000원짜리 디버그용 상품(참고로 PG사마다 결제 최소금액이 있어서 그 이하로는 결제가 안 된다. KCP는 천원이다.) 만들어서 해볼까 했는데, 환불이 너무 쉬워서 결제 기능 테스트할떄 요긴하게 써 먹었다. PG사마다 '테스트 결제'라는 기능이 있긴 한데, 이거는 그냥 잘 돌아가는지 정도 확인하는데만 쓰고, 반드시 실제 결제로 테스트 하는 걸 권장한다. 아래에서 설명하겠지만 결제 모듈은 상상이상으로 까칠해서, 생각 이상으로 안될 때가 많다...
대충 이런 이유로 아임포트를 도입하는게 개발 코스트 절약과 개발자의 정신건강을 위해 좋다. 일단 PG사 하나만 쓰는건 무료고, 여러개의 PG사를 쓸 때만 한번 돈을 지불하고 계정을 업그레이드 하면 된다.
아임포트 docs의 경우엔 '가맹점 정보 확인하기', '일반결제 연동하기', 'IMP.request_pay - param, rsp 객체' 이 세 페이지만 참고해도 기본적인 결제를 구현하는 덴 지장 없을 것이다.
이 과정에서 주의할 점은, 단순히 테스트 결제라면 상관없지만, 실제 결제기능을 위해선 PG사와 계약을 하고 PG사로부터 가맹점 id를 발급받아야 한다. 이 때, 직접 PG사와 계약하면 안되고 아임포트 내의 PG사 가입 페이지를 통해, 아임포트를 거쳐서 계약을 해야 한다. 구조상 아임포트 서버에서 결제가 이루어지기 때문이다. 물론 아예 가맹점 id를 아임포트에서 소유하는 건 아니고, PG사 페이지에서도 정상적으로 가맹점 취급을 받는다.
이걸 모르고 직접 PG사와 계약을 했다가 결제가 안 돼서 아임포트 측에 문의를 하고, 최종적으론 아임포트를 통해 재계약을 하는 등 많은 삽질을 했었다... 참고로, PG사와 계약하는 것도 사업자등록증을 보내거나 쇼핑몰 심사 등의 과정이 있기 때문에 주 단위로 걸린다. 나는 개발 외적인 비즈니스 업무는 맡지 않았지만, 제3자의 눈으로 봐도 수많은 메일과 서류가 오고가는 등 많이 피곤해 보이는 작업이었다.
이게 짧으면 1주일, 길면 2주일 정도고 중간에 뭔가 문제가 있으면 당연히 수정요청을 받는다. 생각보다 심사 조건이 까다롭다. 사이트에 연락처나 계좌 등이 있어야 하고, 상품 갯수도 일정 이상이여야 한다. 사실 상품 갯수도 제한이 있다는 것이 의외였는데, "이걸 누가 사?" 가 절로 나오는 상품을 사이트에 넣으며 불편한 진실을 어렴풋이 깨달았다...
실제 서버를 배포하면, 불행하게도 항상 따라오는 게 버그다. 물론 철저한 코딩과 테스트, 경우의 수 계산으로 미연에 방지하는 게 가장 좋겠지만 현실적으로 불가능하니, 차선책으론 에러가 발생했을 때, 문제 해결을 위한 데이터를 최대한 모으는 게 중요하다고 생각했다.
물론 Django에서 아래와 같이 자체적으로 로깅을 지원하긴 하는데, 특히 이용자가 많아질 수록 텍스트로 이루어진 로그는 보기도 불편하고 무엇보다 내가 원하는 특정 상황(=특정 세션)에 대한 부분만 추출하기 너무 까다로웠다. 그렇다고 설정을 만져 Error 이외의 로그를 거르기엔 뭔가 찝찝했다.
그래서 무료로 이용할 수 있는 에러 모니터링 툴에 대해서 찾아보던 중, Sentry에 대해 알게 되었다. 그래서 실제 서비스에 적용해서 사용해 보니, 매우 간편하면서 강력해서 큰 도움이 되었다. 그래서 센트리의 설치나 간단한 활용법에 대해서 공유하고자 한다.
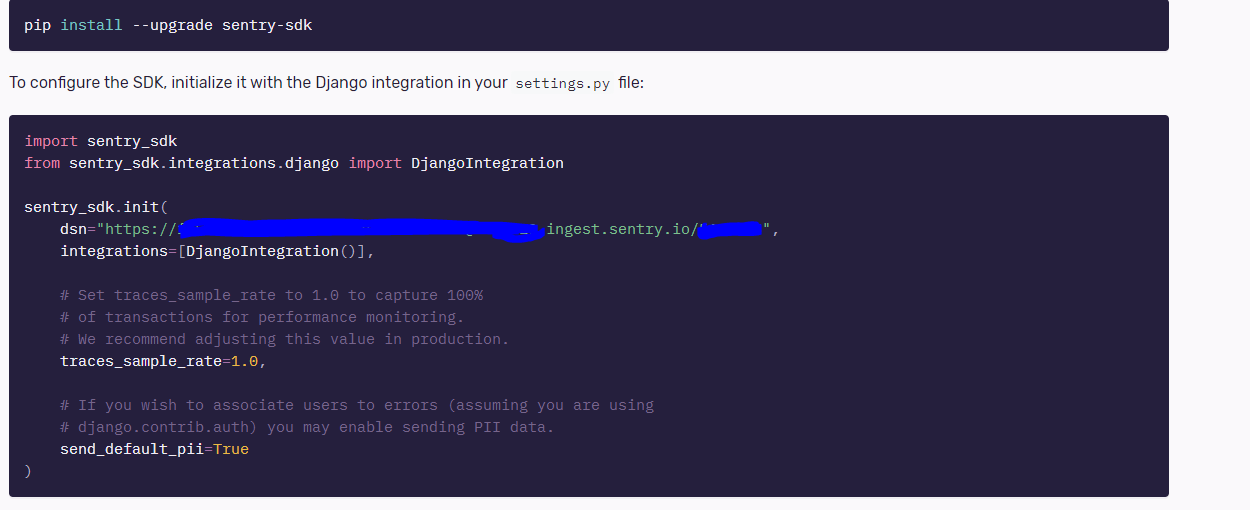
간단히 회원가입하고, 바로 프로젝트를 하나 만들면 된다. 프로젝트에서 모니터링을 진행할 프로그램을 지정할 것이다. 자기가 사용하는 언어/프레임워크를 고르면 그에 맞춰서 코드를 만들어 준다. Python -> Django를 고르면 된다. 그러면 아래와 같이 하라는 튜토리얼 페이지가 뜬다.
sentry-sdk 라이브러리를 설치하고 Settings.py에 넣으면 된다. 물론 위 정보는 프로덕션 서버의 설정 파일에 따로 넣는 것을 추천한다. 필요하지 않다면 개발 서버에서는 굳이 에러 트레킹을 할 필요가 없기 때문이다.
그 아래는 0으로 나누기 에러를 발생시키고 테스트 해보는 부분이 있는데, 간단한 테스트이므로 가볍게 한번 해 보면 될 것이다.
2. 활용하기 - 프로젝트
프로젝트 세팅을 마친 후, 화면을 살펴 보자. 왼쪽의 목록에서 여러 가지 메뉴들이 있는데, 차례대로 Projects, Issues, Performance를 살펴볼 예정이다. 우선 Projects 메뉴에 가서, 만든 프로젝트를 눌러 보자.
이 화면은 프로젝트 상세 페이지이다. 내가 돌리고 있는 현재 서버의 상태를 전체적으로 조망할 수 있다.
Crash Free Sessions는 에러 없이 정상적으로 진행된 요청의 비율을 나타낸다. 당연히 이 비율이 높아야 서버가 정상적으로 돌아가고 있다고 간주할 수 있을 것이다. 내 서버는 약 99.9%의 신뢰도를 나타내고 있다. 이 0.1%가 왜 생겼는지는 아래에서 설명하도록 하겠다.
Number of Releases는 이 프로젝트가 가진 릴리즈의 수인데, 쉽게 말해서 웹 서버의 버젼이 몇 개가 있었는지, 즉 몇 번의 변화가 있었는지를 뜻한다. 나는 따로 관련 설정을 안 해서 0이라고 나왔다. 아마 설정을 하면 특정 버젼에선 에러가 많았고 특정 버젼에선 적었다 식으로 모니터링이 가능할 텐데, 굳이 이 기능이 필요할 것 같진 않아서 나는 쓰지 않았으니 관심 있다면 사용해 봐도 될 것이다.
Apdex는 성능 관련 지표인데, 지정된 시간 안에 요청에 대한 응답이 왔는지에 대한 비율이다. 이건 Settings->Perfomance에 가면 해당 값이 있는데, 기본값으론 300ms가 설정되는 것 같다. 성능 트래킹을 원한다면 이 부분도 활용할 수 있을 것이다.
3. 활용하기 - 이슈
Issues 페이지이다. 사실 센트리를 즐겨찾기에 설정해 놨는데, 들어가면 자동으로 이 페이지로 뜬다. 그만큼 사실상 센트리에서 가장 중요한 부분 중 하나이다. 여기서 서버에서 발생한 에러들을 관리할 수 있다. 발생 시간이나 에러 내용, 어떤 URL로 접속했을 때 에러가 발생했는지 등이 적혀 있다. 여러번 발생하는 에러는 아래와 같이 이벤트(=요청 횟수)와 유저를 구분하여 중첩되어 기록된다. 즉, 여러 명의 유저가 이런 문제를 겪은 건지, 아니면 한 명이 똑같은 에러를 여러 번 발생시킨 건지 구분할 수 있다. 이 점이 Sentry가 에러를 보기 편하게 해주는 강점 중 하나라고 생각한다.
참고로, 에러들이 꽤 많이 떠 있는데, 장고 서버를 운영하면서 몇 가지 발생할 수 있는 에러들이 있다.
우선Invalid HTTP_HOST header: 'www.blockfinex.com'. You may need to add 'www.blockfinex.com'... 등등 HTTP_HOST 에러가 대부분인데, 이건 유저가 아니라 그냥 인터넷 사이트들을 무차별적으로 취약점 스캔하는 봇들이다. 자세히 보면 접근하는 URL도 정상적이지 않다. 아무나 걸려라 하는 식으로 스캔하고 다니는 거라, 에러가 나면서 차단당하는 게 맞다. 해당 에러는 설정을 통해 이 유형의 에러는 무시하도록 할 수 있는데, 혹시 진짜 관찰이 필요한 에러들도 무시될까봐 따로 건들지 않았다.
참고로 settings.py의 ALLOWED_HOST를 설정하지 않거나 *(모든 호스트 허용)으로 해 두면 이 에러는 안 뜰 것이다. 보안에 좋지 않으니 *보다는 실제 사용하는 호스트 이름으로 설정해 두자... 잘 모르겠으면 [{서버의 공인 아이피 주소}, '127.0.0.1', {서버의 도메인 주소}] 정도로만 해 둬도 될 것이다.
인터넷에 공개된 서버라면 반드시 받을 수밖에 없는 공격이다...
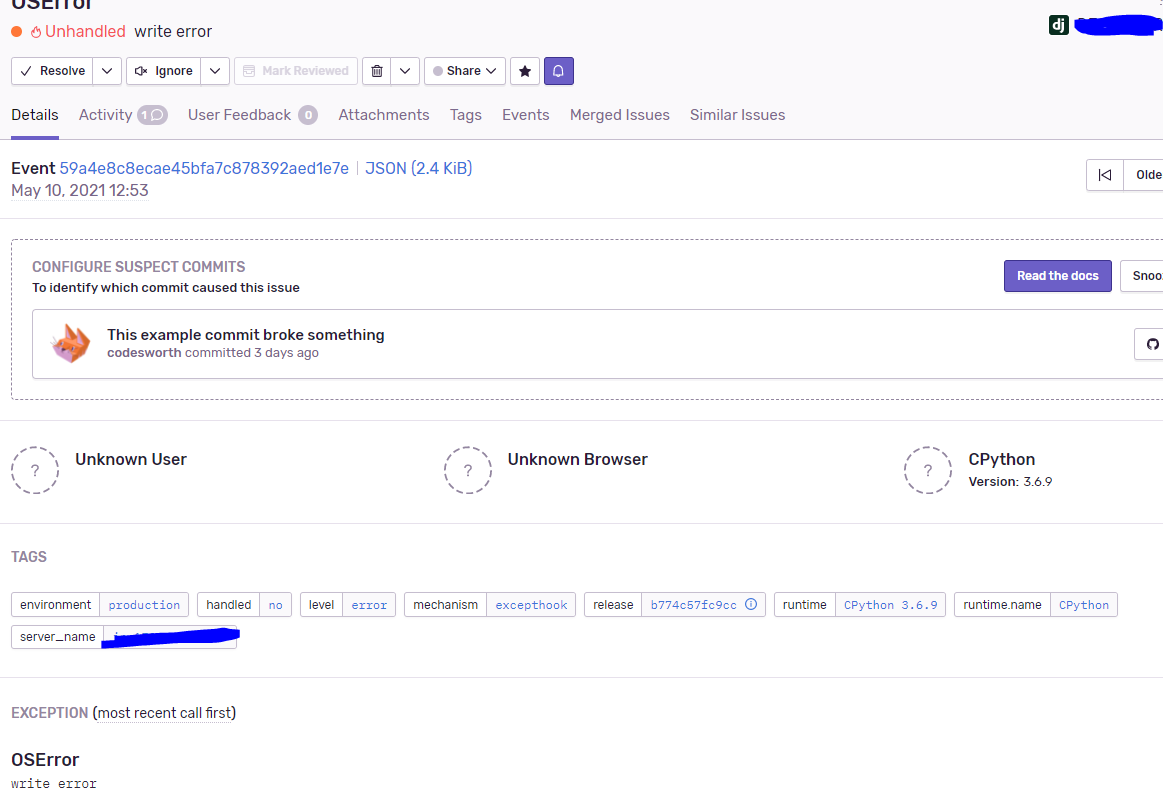
그리고, OSError 같은 경우엔 개발 환경에서는 발생하지 않았지만 프로덕션 환경에서는 주기적으로 발생하던 에러인데, 이 에러는 다른 에러들과 다르게 Django의 세션 관련 데이터가 누락되어 있다.
장고와 관련된 정보가 아예 누락되는 걸로 봐선 장고 밖에서 발생하는 에러로 추정되는데, 구글링 결과 장고의 문제는 아니고 wsgi로 사용하는 프레임워크인 uwsgi 관련 버그였다.
쉽게 말해서, 클라이언트와 서버가 요청을 주고받는 중 클라이언트는 어떤 이유로던 통신을 끊었는데, 서버(정확히는 uwsgi)에서는 요청을 계속 처리하고 있어서 생기는 오류이다. 이건 서버 설정을 만지면 해결될 수 있는 오류이다. 사실 이 에러 때문에 서비스에 문제가 생긴 적은 없었던 것 같다...
4. 활용하기 - 이슈 - 에러 상세보기
위에 뜬 에러들 중 하나를 눌러 보면 에러의 상세한 내용을 볼 수 있다. 아래는 실제로 발생한 에러를 캡처한 것이다.
우선 우측 상단의 이벤트, 유저를 통해 1명의 유저에게 이 에러가 12번 발생했다는 것을 알 수 있다. 또한, 해당 유저가 사용했던 브라우저와 운영 체제 역시 확인할 수 있다. 현재 보고 있는 건 가장 최근에 발생한 에러 정보로, 이전에 발생한 에러 정보를 보고 싶다면 events 아래의 숫자를 클릭하면 지금까지 발생한 동일한 에러 리스트가 뜬다. 각각을 클릭하면 각 에러에 대한 정보를 알 수 있다.
또한, users 밑의 숫자(1)을 클릭해도 해당 에러를 겪은 유저들의 목록과 비율이 표시된다.
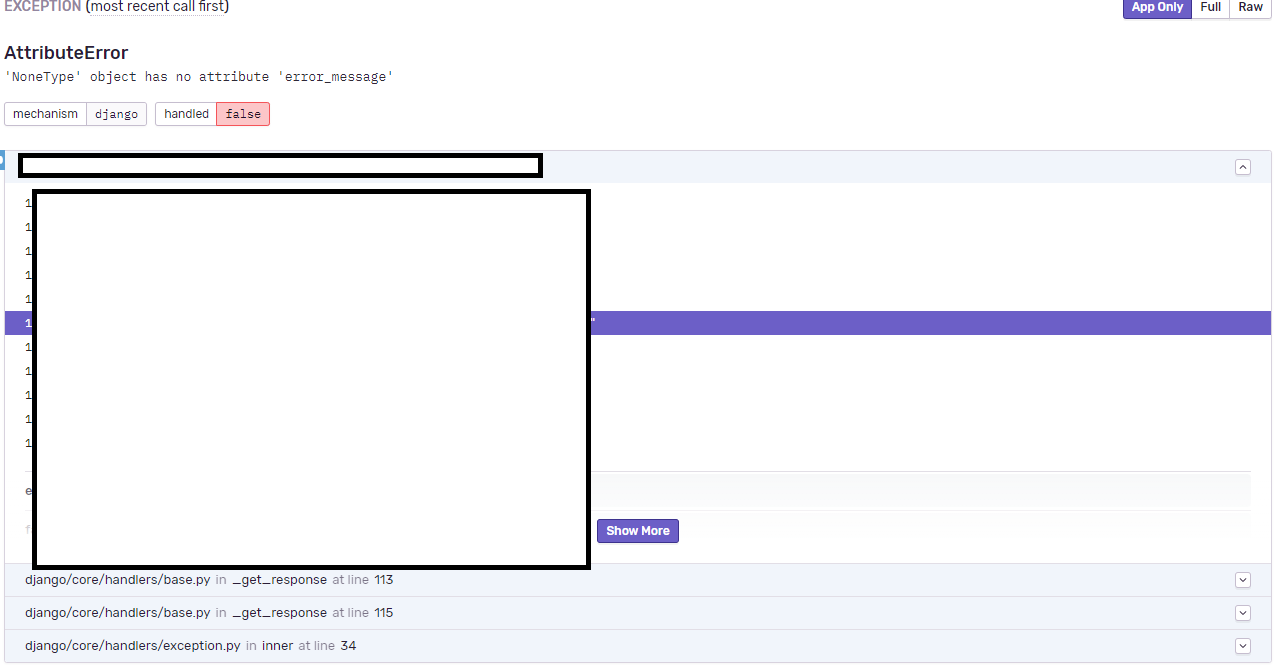
센트리에서 에러가 발생한 상황의 정보를 수집하여 보여주는데, 우선 실행시킨 코드에서 에러가 발생한 부분을 표시해 준다. 여기는 기존 파이썬에서 보여주는 StackTrace와 같다.
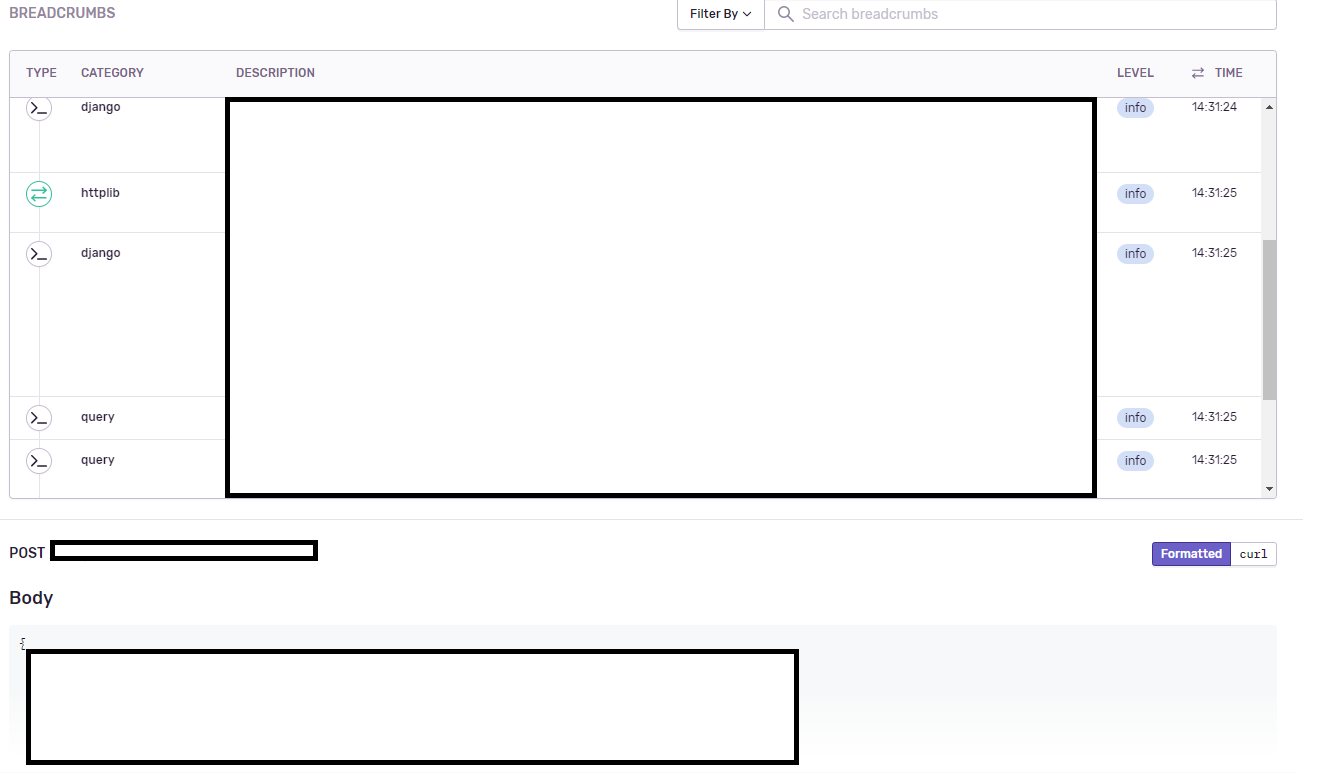
다음으로, breadcrumbs라 해서 사용자가 사이트에서 어떤 행동을 했는지 보여준다. 이 부분이 가장 핵심인데, Django 로거의 info 로그는 물론, 해당 사용자의 요청으로 인해 발생한 추가적인 HTTP 요청(심지어 타 사이트에 대한 API 요청이다)이나 DB 조작도 모두 보여준다. 이 부분을 보안상 가려야 하는 것이 유감일 정도로 상세하게 나온다. '카테고리(CATEGORY)'에서 httplib은 HTTP 요청, query는 DB 쿼리, django는 Django 로거를 나타낸다. 아마 더 많은 종류가 있을 것이다.
그리고, 해당 view는 body에 데이터를 담은 POST 요청을 받아 특정한 동작을 수행하는데, 이 POST 요청에 대한 정보 역시 body의 내용을 포함해 쿠키, 헤더 등 모든 정보가 기록된다. 이외에도, 현재 유저가 django의 auth 시스템을 이용해 로그인 된 상태라면 해당 유저의 정보 역시 기록된다.
Details 옆에 Activity 탭에서는, 해당 에러에 대해 기록을 할 수 있다, 깃헙의 issue와 비슷하다. 아마 여러 명이서 협업을 할 때 담당자를 배정하고, 의견 등을 교환하는 데 사용할 수 있을 것이다. 물론 아래처럼 그냥 개인 메모용으로 써도 된다.
마지막으로, 특정 에러에 대해 Resolve나 Ignore 등으로 체크를 할 수 있다. Resolve는 해결됨, Ignore는 무시이다. 체크할 시 해당 에러에 대해서 빨리 해결하라고 굵은 글씨로 강조하지 않게 된다. 단, 이그노어의 경우엔 이미 발생한 해당 에러에 대해서만 무시이고, 아예 관련 에러를 전체적으로 무시하려면 설정을 만져야 한다.
이외에도 특정 에러 발생시 이메일 등으로 알림을 날리는 기능도 있지만 아마 간단히 활용하는 데는 이 정도만 해도 충분할 것이다.
5. 성능 분석
이건 에러 모니터링과는 크게 관련은 없는 기능인데, 성능 측정엔 도움이 되는 부분이다. Perfomance에 들어가면 볼 수 있다.
서버의 성능과 관련된 각종 지표들을 볼 수 있는 곳이다. 만약 데이터가 표시되지 않는다면 오른쪽 위의 기간을 좀 더 넓게 만져보자. Duration p75는 75%의 요청이 해당 시간보다 빠르게 처리되었다는 뜻이고, throughput은 분당 해당 수치만큼의 요청이 들어왔다는 뜻이고, Failure rate는 말 그대로 에러가 난 비율(HTTP 코드 4XX), apdex는 위에서 설명한 대로 제한 시간 내에 요청이 처리되었는지의 비율이다. 아래에는 관련 그래프들이 나타나 있다.
Failure Rate가 꽤 높다. 대략 5명 중에 한 명이 오류가 난다는 것인데, 사실 정상이다. 왜냐하면 위에서 말한 취약점 스캔 봇들이 상상 이상으로 엄청나게 긁어가기 때문이다. 어떤 요청들이 있었는지 이 성능 페이지에서 바로 확인할 수 있는데, 한번 살펴보자.
php를 사용하지도 않는 사이트인데 관련 URL로 많이 들어온다. 저게 워드프레스 쪽에서 사용되는 관리자 페이지나 설정 파일인데, 아무나 걸려라식 무차별 대입 공격이고 내 서버에는 저런 파일들이 존재하지 않으므로 전부 404 Not Found로 표시되는 것이다. 이게 바로 20%의 failure rate의 정체이다.
위에서 소개한 센트리의 기능들은 극히 일부이다. 일단 무료 버젼에 있는 기능들만 소개한 거고 아마 유료 버젼엔 더 많은 기능들이 있을 것이다. 무료 기능으로도 꽤나 유용하게 사용할 수 있고 무엇보다 설치가 매우 간편하다는게 마음에 들었다. 장고 서버가 있다면 에러 모니터링을 공부해 보는 용도로도 유용할 것 같다.
매일 오전 4시에 backupdb.sh를 실행하고, 이를 db_backupdb.log에 로깅한다는 간단한 내용이다.
이렇게 작성하고 자고 일어나보니 아무 일도 없었다... 해결하면서 여러 가지 문제들을 겪었는데, 여기서 겪었던 크론탭을 사용하면서 겪었던 관련 문제점들과 해결책을 소개한다.
0. 크론탭 로그 확인
일단 당연히 문제가 일어났으면 기본적으로 로그를 확인해야 한다. ubuntu 18.04 기준으로 크론 관련 로깅은 기본적으로 /var/log/syslog에 기록되니 여기를 뒤져보면 되는데, 문제는 여긴 시스템 관련 로깅들이 다 같이 작성되는 곳이다 보니 AWS EC2에선 워낙 별별 로그가 많다. 그래서 아래의 명령어로 뒤져보면 크론 관련 메세지만 나와서 보기 편하다. 여기서부터 원인을 찾기 쉬울 것이다.
cat /var/log/syslog | grep CRON
1. (CRON) info (No MTA installed, discarding output)
여기서 말하는 MTA는 Mail Transfer Agent로 메일 에이전트이다. 메일 에이전트가 없다니까 그냥 메일 에이전트를 깔면 해결되고, sudo apt-get install postfix 한 방이면 이 오류는 사라질 것이다. 문제는 이 오류가 왜 생기냐는 건데, 바로 내가 추가했던 로그 파일 때문이다.
크론 데몬의 로깅은 다른 데몬들처럼 로그 파일을 /var/log 이런데 작성하는 게 아니라, 메일 에이전트를 통해서 해당 크론탭을 소유한 각 유저에게 로그 내용이 전송된다. 나는 이 내용을 파일에 기록하도록 했으니 그 내용이 파일로 작성되어서, 다른 로깅들처럼 파일로 작성되는 것처럼 보이는 것이다. 왜 이런 식으로 처리되냐면, 리눅스는 여러 명의 유저들이 동시에 사용하는 것을 전제로 계정 시스템이 구현되어 있고, 크론탭 역시 각 유저별로 따로 작성되기 때문에 각 유저별로 따로 로그를 관리할 필요가 있기 때문이다. 만약 /var/log 아래에 로그가 한꺼번에 기록된다면, 루트 계정의 크론 로그는 일반 계정이 보면 안되니 읽기 권한에 제한을 줘야 하는 일이 발생한다. 그러면 당연히 일반 유저들은 자신의 로그를 확인할 수 없는 모순이 생긴다.
로그 파일을 열면 이렇게 뜨기 때문이다. 나는 cat 명령어로 이 파일을 여는데 문제가 생긴 줄 알았다. 그래서 혹시 로그 생성중에 뭔가 문제가 생겨서 깨진 파일이 생성됐나 확인해 보려고 크론 관련 로그를 뒤지고, 기본 쉘이 /bin/bash에서 /bin/sh로 바뀌었나 점검해 봤는데 아니었고 그냥 로그 파일이 저래 나온 거였다. vim db_backupdb.log로 열어보면 정상적으로 열리고 내용도 저거 한줄이다. ㅡㅡ;
아무튼 이 오류는 왜 생기냐면 쉘 스크립트를 실행하기 위해 쓴 명령어 source가 문제였다. 크론탭에서 사용하는 기본 쉘이 /bin/sh인데, 이 쉘은 /bin/bash와 달리 source 명령어를 지원하지 않는다. 그래서 source 명령어를 찾지 못해서 스크립트를 실행조차 못하고 끝났던 것이다. 그래서 1. 크론탭에서 사용하는 쉘을 바꾸거나 2. /bin/sh에서 사용할 수 있는 명령어를 사용하면 해결된다. 즉, 아래의 두 가지 방법중 하나만 하면 된다.
파이썬에서 패키지 의존성을 공유할 때 가장 범용적으로 사용되는 게 requirements.txt일 것이다. 현재 파이썬 환경에서 설치된 패키지들을 정리할땐 아래의 명령어를 사용한다.
pip freeze > requirements.txt
이 명령어를 통해 설치된 패키지들이 requirements.txt에 나열된다. 이 파일을 이용하여 패키지들을 설치하고자 할 때는, 다음과 같은 명령어를 사용한다.
pip install -r requirements.txt
보통은 이 두가지 명령어 정도면 프로젝트를 관리하는 데는 지장이 없을 것이다. 하지만, 상황별로 패키지를 다르게 관리해야 할 때도 있을 것이다. 나의 경우엔, 윈도우즈 PC에서 개발을 하고 우분투 기반의 서버에서 배포를 하는데, 서버에서 위 명령어를 이용하여 패키지들을 설치할 때 오류가 생겼었다. 그래서 오류가 나는 패키지를 찾아봤는데, pywin32라는 라이브러리였고, 이 라이브러리는 파이썬에서 윈도우즈 API들을 사용할 때 쓰는 라이브러리라 당연히 에러가 날 수 밖에 없었다. 그래서, 상황에 의존성을 따로 관리해야 할 필요성을 느꼈다.
물론 일회성이고, 문제가 되는 패키지가 한두개라면 그냥 복붙으로 파일을 새로 만들고 위처럼 해도 된다. 하지만 관리해야 할 패키지가 수십 개라면 저 방법은 너무 귀찮고 헷갈릴 것이다. 그래서 조금 더 우아한 방법이 있다.
2. 조건에 따른 패키지 설치
# requirements.txt
Django==3.0.8
django-import-export==2.3.0
django-sass-processor==0.8
django-suit==2.0a1
et-xmlfile==1.0.1
Flask==1.1.2
Flask-BasicAuth==0.2.0
pycparser==2.20
pytz==2020.1
pywin32==300; sys_platform == 'win32' - 문제가 되는 라이브러리
조건을 붙이길 원하는 패키지의 뒤에 ;를 붙이고, 조건을 넣는다. 나는 윈도우즈 플랫폼에서만 해당 패키지를 설치하길 원해서 윈도우즈 플랫폼에서만 해당 라이브러리를 설치하도록 설정하였다. 만약 리눅스에서만 설치하기 원하는 패키지라면 sys_platform == 'linux' (python2는 linux2)로 설정하면 된다.
위 내용에 대한 정보는 여기를 참조하면 된다. 해당 문서에서 소개하는 주요 마커들은 다음과 같다.
예를 들어, 파이썬의 버젼(2.7, 3.5, 3.6, ...)에 따라서도 다르게 설정하길 원한다면 python_version == "원하는 버젼"을 붙이면 될 것이다.
3. 파일을 아예 분리하기
위에 제시된 마커들로는 구분할 수 없는 정보가 있거나, 분리해야 하는 패키지가 너무 많다면 아예 파일을 나눠버릴 수 있다.
이런 식으로, 다른 파일을 읽어오도록 설정할 수 있다. 예를 들어, 배포 환경에선 `pip install -r requirements-production.txt` 명령어를 실행한다. 그러면 우선 requirements.txt를 읽어와서 그 안의 패키지를 설치하고, 그 다음엔 requirements-production.txt 에 적혀 있는 라이브러리들을 설치하게 된다. gunicorn, uwsgi와 같은 배포에만 필요한 라이브러리들이 여기에 들어가면 될 것이다.
관리해야 하는 패키지들이 간단하다면 역시 파일 하나로 모든 게 가능한 2번 방법, 조금 구조가 복잡하다면 3번 방법이 가장 적절할 것이다. 자세한 정보는 여기서 확인할 수 있다.